近期,苹果公司在视觉模型自回归预训练领域取得了重要进展,并将这一技术扩展至多模态环境,即同时处理图像与文本数据。为了进一步推动这一领域的研究与发展,苹果团队推出了AIMV2——一系列具有广泛适用性的视觉编码器。
- GitHub:https://github.com/apple/ml-aim
- 模型:https://huggingface.co/collections/apple/aimv2-6720fe1558d94c7805f7688c
AIMV2的特点
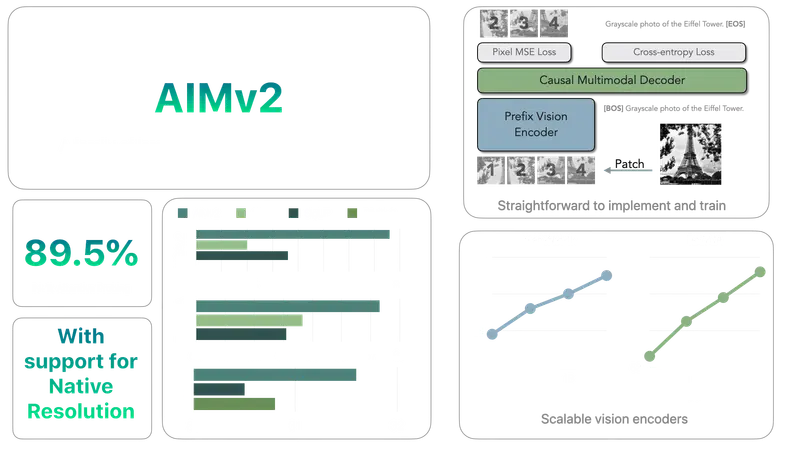
AIMV2的核心优势在于其简洁而高效的预训练流程,具备强大的可扩展性。此外,它在多种下游任务中的表现尤为突出。这些特性得益于一种创新的设计:将视觉编码器与一个能够自回归生成原始图像块和文本标签的多模态解码器相结合。
技术突破
AIMV2不仅在多模态评估中展现出卓越的能力,还在传统的视觉任务中实现了显著的性能提升,包括但不限于对象定位、基础识别及分类等。具体而言,AIMV2-3B版本的编码器在保持主干架构不变的情况下,在ImageNet-1k数据集上的分类准确率达到了89.5%,这一成绩令人瞩目。
主要功能和特点:
- 多模态预训练:AIMV2通过与多模态解码器配对,自回归地生成原始图像块和文本标记,实现图像和文本的联合学习。
- 卓越的性能:在ImageNet-1k数据集上,AIMV2-3B编码器在冻结模型主体的情况下达到了89.5%的准确率。
- 与现有技术的比较:AIMV2在多模态图像理解方面,一致性地超越了现有的最先进对比模型(例如CLIP, SigLIP)。
- 简单易实现:AIMV2易于实现和训练,不需要非常大的批量大小或特殊的批间通信方法。
- 与大型语言模型(LLM)的兼容性:AIMV2的架构和预训练目标与LLM驱动的多模态应用非常匹配,可以实现无缝集成。
工作原理:
AIMV2的工作原理基于自回归预训练框架,将图像分割成不重叠的图像块序列,并将文本序列分解为子词。这些序列被连接起来,允许文本标记关注图像标记。模型通过自回归方式预测序列中的下一个标记,无论当前处理的是图像还是文本标记。预训练设置包括一个专门的视图编码器处理原始图像块,然后将其传递给多模态解码器,解码器随后对组合序列执行下一个标记预测。
具体应用场景:
- 图像识别:使用冻结的AIMV2模型作为特征提取器,在多个图像识别基准上进行评估。
- 目标检测和实例分割:将AIMV2作为Mask R-CNN模型的主干网络,用于目标检测和实例分割任务。
- 多模态理解:在多模态指令调整和大规模多模态预训练设置中,AIMV2作为视觉编码器,与大型语言模型结合,进行多模态任务的处理。
- 零样本学习:通过LiT(Locked-Image Text Tuning)技术,AIMV2能够在零样本设置中进行有效的迁移学习。
性能对比
与其他领先的多模态图像理解模型(例如CLIP、SigLIP)相比,AIMV2在不同应用场景下均显示出优越的表现。无论是在标准视觉任务还是复杂的多模态挑战中,AIMV2都展现出了强大的竞争力。