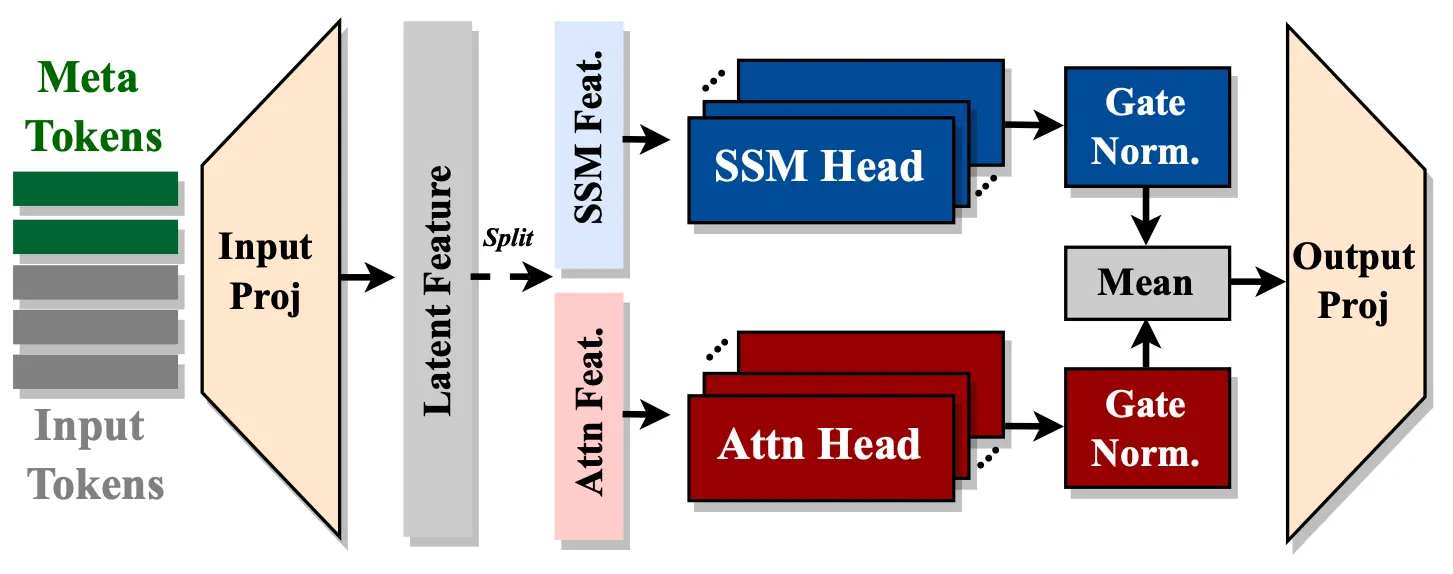
英伟达推出一种新型的小规模语言模型——Hymba。Hymba采用了混合头架构(Hybrid-head Architecture),这种架构结合了变换器(Transformer)的注意力机制和状态空间模型(State Space Models, SSMs),以提高效率。Hymba的主要特点是在同一个层内集成了注意力头和SSM头,提供并行和互补的处理方式,同时引入了可学习的元令牌(meta tokens),这些元令牌被添加到输入序列的前面,存储关键信息,减轻了注意力机制的负担。
- GitHub:https://github.com/NVlabs/hymba
- 模型:https://huggingface.co/collections/nvidia/hymba-673c35516c12c4b98b5e845f
例如,我们有一个问答系统,用户问:“法国的首都是什么?”Hymba模型能够理解这个问题,并从其训练数据中提取出“巴黎”作为答案。由于Hymba的混合头架构和元令牌,它能够有效地处理和回忆相关信息,即使在面对大量数据时也能保持高效率和准确性。
主要功能和特点:
- 混合头架构:Hymba结合了注意力头和SSM头,使得模型能够同时利用注意力机制的高分辨率回忆和SSM的高效上下文总结。
- 元令牌:引入可学习的元令牌,这些令牌作为输入序列的前缀,与所有后续令牌交互,存储关键信息,减轻了注意力机制的负担。
- 跨层键值共享:通过在连续层之间共享键值(KV)缓存,减少了内存使用和模型参数。
- 部分滑动窗口注意力:大多数层采用滑动窗口注意力,进一步降低了缓存成本。
- 高效性能:Hymba在小规模语言模型中取得了最先进的结果,例如Hymba-1.5B-Base模型在性能上超过了所有小于2B的公共模型,甚至在平均准确率上超过了Llama-3.2-3B。
工作原理:
Hymba的工作原理基于混合头模块,该模块并行处理输入信息,使得不同的注意力和SSM头可以以不同的方式存储、检索和处理相同的信息。这种设计使得Hymba能够同时利用注意力机制的高分辨率回忆和SSM的高效上下文总结。此外,元令牌作为输入序列的前缀,参与所有后续令牌的注意力和SSM计算,类似于人脑中的元记忆,帮助识别在其他记忆中定位所需信息的位置。
具体应用场景:
- 常识推理任务:Hymba在常识推理任务中表现出色,能够理解和推理关于世界的基本知识。
- 问答系统:Hymba可以用于构建问答系统,通过理解问题并从给定的文本中提取答案。
- 文本摘要和生成:Hymba可以用于生成文本摘要或根据给定的指令生成新的文本内容。
- 指令遵循:Hymba还可以用于需要遵循复杂指令的场景,如编程语言的理解和执行。