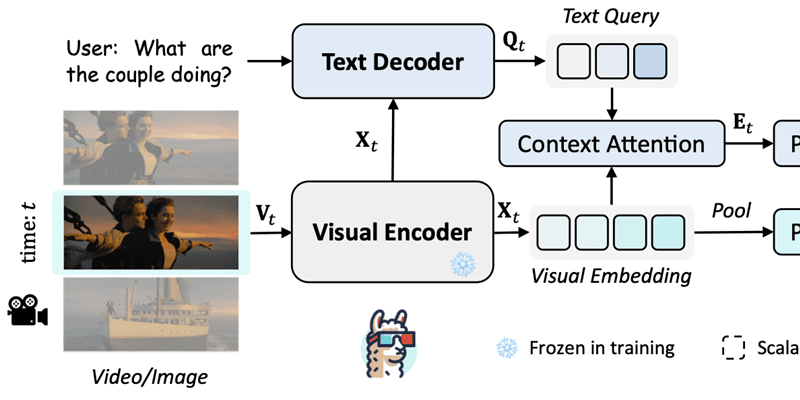
由香港中文大学贾佳亚团队推出的多模态大模型LLaMA-VID近期上架GitHub,LLaMA-VID支持单图、短视频甚至长达3小时电影的输入处理,大模型可以读懂图甚至是一部电影,你可以与它进行聊天让它为你总结,贾佳亚团队重新设计了图像的编码方式,采用上下文编码 (Context Token) 和图像内容编码 (Content Token) 来对视频中的单帧进行编码,从而将视频中的每一帧用2个Token来表示。
这是贾佳亚团队自8月提出主攻推理分割的LISA多模态大模型、10月发布的70B参数长文本开源大语言模型LongAlpaca和超长文本扩展术LongLoRA后的又一次重磅技术更新。而LongLoRA只需两行代码便可将7B模型的文本长度拓展到100k tokens,70B模型的文本长度拓展到32k tokens的成绩收获了无数好评。
项目地址:https://llama-vid.github.io
GitHub地址:https://github.com/dvlab-research/LLaMA-VID
Demo地址:http://103.170.5.190:7864
目前Demo仅支持短视频,如果你在本地安装此应用,那么定制短视频聊天,请选择llama-vid-vicuna-7b-short模型;如果您想与预加载的长电影聊天,请选择 llama-vid-vicuna-7b-long模型,官方演示是在单个 3090 GPU 中实现,在该演示中支持 30 分钟的视频,所以大家还是看下自己的显卡是否支持吧!目前聊天也仅支持英文,官方给出的安装步骤也是针对Linux,如果感兴趣大家可以自行研究。