
在今年 6 月份的 I / O 开发者大会上,谷歌 CEO 皮查伊首次公告了新一代人工智能模型Gemini,从9月份开始小范围测试,今天谷歌正式发布了「Gemini 1.0」,在官方博客的介绍中, CEO 皮查伊表示:这是首个「新一代的 AI 模型」,并且以「人们理解世界,并且与世界互动的方式」为灵感来源。 Gemini 1.0 是谷歌的 DeepMind 与研究部门通力合作的成果,在功能上完全不输目前世面上最先进的 AI 模型,甚至在大部分基准测试中完全击败了 OpenAI 的 GPT-4,皮查伊称它的能力「在各个领域都是最尖端的」。

目前针对不同场景,谷歌发布了三种不同版本:Gemini Ultra、Gemini Pro 和 Gemini Nano,不同的版本也将适用于不同的场景和案例:
-
Gemini Ultra - 用于处理高度复杂任务的最强、最大的模型。
-
Gemini Pro - 用于扩展各种任务的最佳模型。
-
Gemini Nano - 用于手机等设备的最高效模型。
从今天(12/6)开始,Google Bard已经开始使用一个微调过的Gemini Pro版本,可提供更高级的逻辑推理、规划和理解能力。目前先释出英语版,可再全球170个国家和地区使用,预计近期会支持更多语言。安卓开发人员还将能够借助 AICore(PS:一种在 Android 14 中提供的全新系统功能)构建 Gemini Nano,终端设备则将率先支持 Pixel 8 Pro 系列机型。
从 12 月 13 日开始,开发者和企业客户将可以通过 Google AI Studio 或 Google Cloud Vertex AI 访问 Gemini Pro 的 Gemini API。Gemini Ultra 目前只提供给被邀请的客户、开发者、合作伙伴以及安全专家进行早期安全测试和反馈,并计划于明年初向开发者和企业客户推出。不过,谷歌没有透露Ultra版更明确的释出时间。未来几个月,Gemini 将应用于谷歌更多的产品和服务,如搜索、广告、Chrome 浏览器和 Duet AI。
Gemini的性能
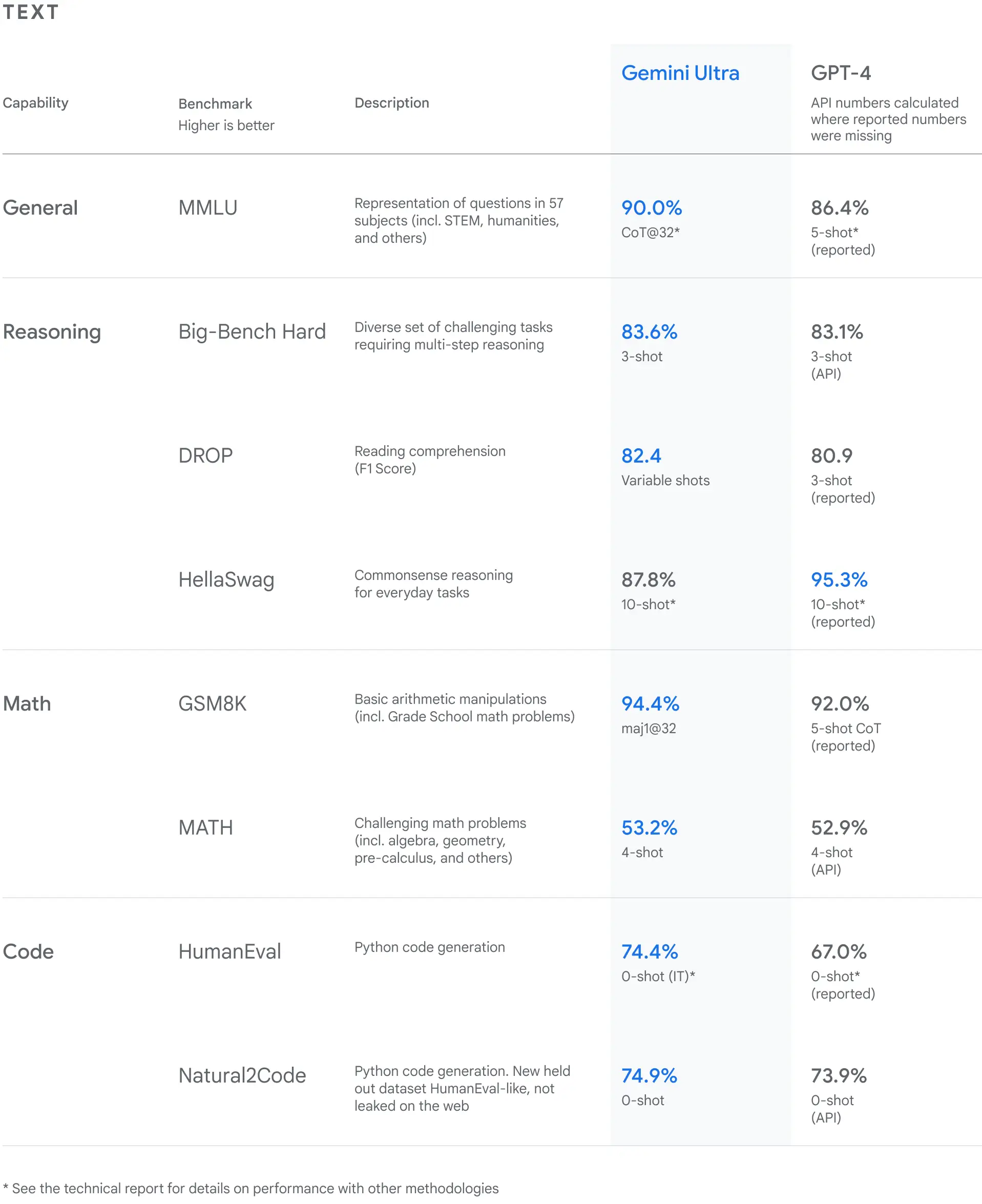
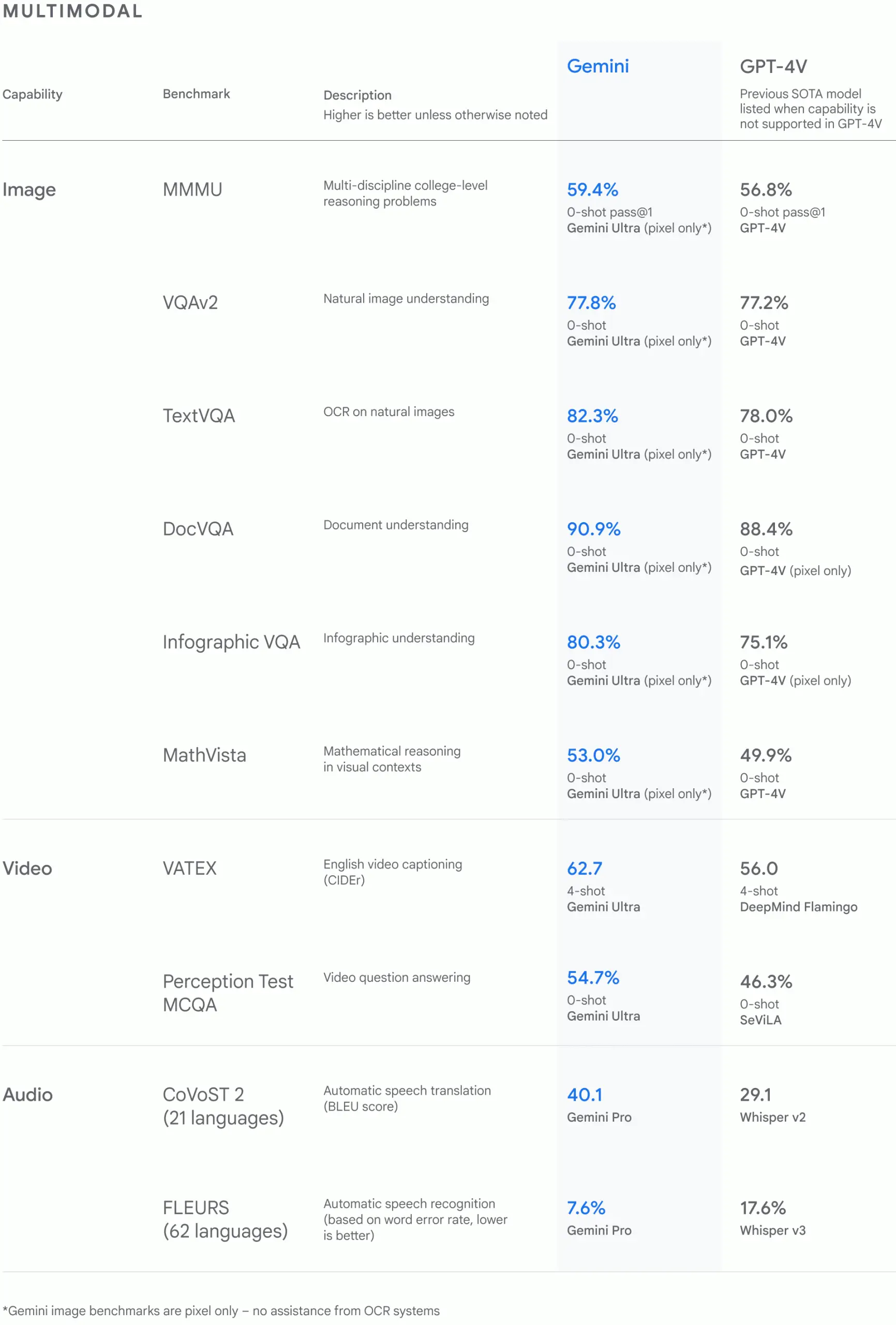
谷歌对 Gemini 模型进行了严格的测试,并评估了它们在各种任务中的性能。从自然图像、音频和视频理解到数学推理,Gemini Ultra 在大型语言模型 (LLM) 研发中广泛使用的 32 个学术基准中的 30 个基准上的性能都超过了目前最先进的结果。Gemini Ultra 的得分率高达 90.0%,是首个在 MMLU(大规模多任务语言理解)中超越人类专家的模型,MMLU 综合运用了数学、物理、历史、法律、医学和伦理等 57 个科目,用于测试世界知识和解决问题的能力。Gemini Ultra 还在新的 MMMU 基准测试上表现出了 59.4% 的领先级性能,该测试涵盖了“需要深思熟虑的”不同领域的多模态任务。(技术报告)
Gemini的能力
谷歌将 Gemini 设计为原生多模态,从一开始就在不同模态上进行预训练。然后利用额外的多模态数据对其进行微调,以进一步提高其有效性。这有助于 Gemini 从一开始就无缝地理解和推理各种输入,远远优于现有的多模态模型,而且它的功能几乎在每个领域都是最先进的。
- 复杂的推理:Gemini 1.0 具有复杂的多模态推理能力,可帮助理解复杂的书面和视觉信息。这使它在发掘海量数据中难以辨别的知识方面具有独特的技能。它通过阅读、过滤和理解信息,从成千上万份文件中提取洞察力的非凡能力,将有助于在从科学到金融的许多领域以数字速度实现新的突破。
- 理解文本、图像、音频等:Gemini 1.0 经过训练,可以同时识别和理解文本、图像、音频等,因此它能更好地理解细微信息,并能回答与复杂主题相关的问题。这使它尤其擅长解释数学和物理等复杂学科的推理。
- 高级编程能力:Gemini 1.0可以理解、解释和生成世界上最流行的编程语言(如 Python、Java、C++ 和 Go)的高质量代码,它能够跨语言工作并对复杂信息进行推理,这使它成为世界领先的编程基础模型之一。使用Gemini的专门版本,谷歌创建了一个更高级的代码生成系统AlphaCode 2,它擅长解决竞争性编程问题,这些问题超出了编程范围,涉及复杂的数学和理论计算机科学。
- 更可靠、更可扩展、更高效:Gemini使用了谷歌自行开发的芯片TPU训练而成,而且使中了v4和v5e版TPU。谷歌同时宣布了新版TPU v5p,可用来加速Gemini模型的开发,供企业用来定制化训练自己的LLM模型。