文章目录[隐藏]
- [t-success icon='']AI·快讯[/t-success]
- 1、OpenAI 仍坚持售股计划,并将多给员工一个月时间考虑是否参与
- 2、昆仑万维发布“天工SkyAgents”平台
- 3、亚马逊推出 Titan 系列 AI 模型:可生成图片及文本、号称兼顾价格和性能
- 4、DeepMind 推出 AI 工具 GNoME,号称已发现 220 万种新晶体材料
- 5、未来有望抽管血就可诊断和预测老年痴呆,科学家研发出新 AI 算法
- 6、Meta开源实时翻译系列模型Seamless
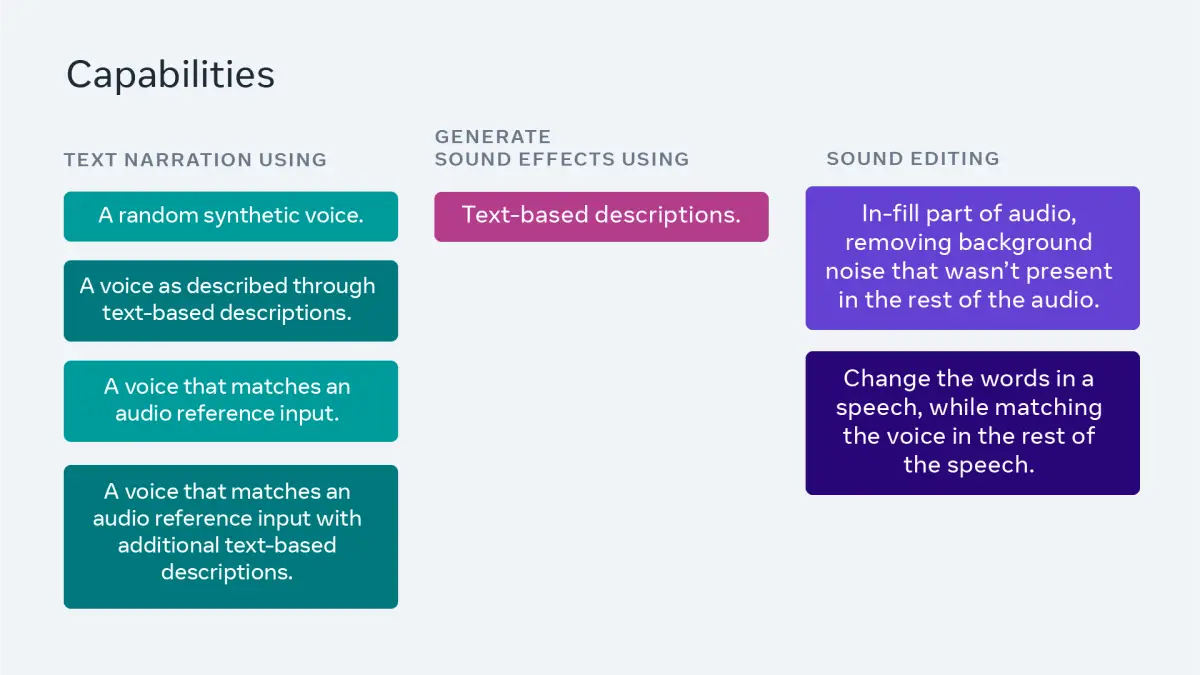
- 7、Meta推出音频生成模型Audiobox
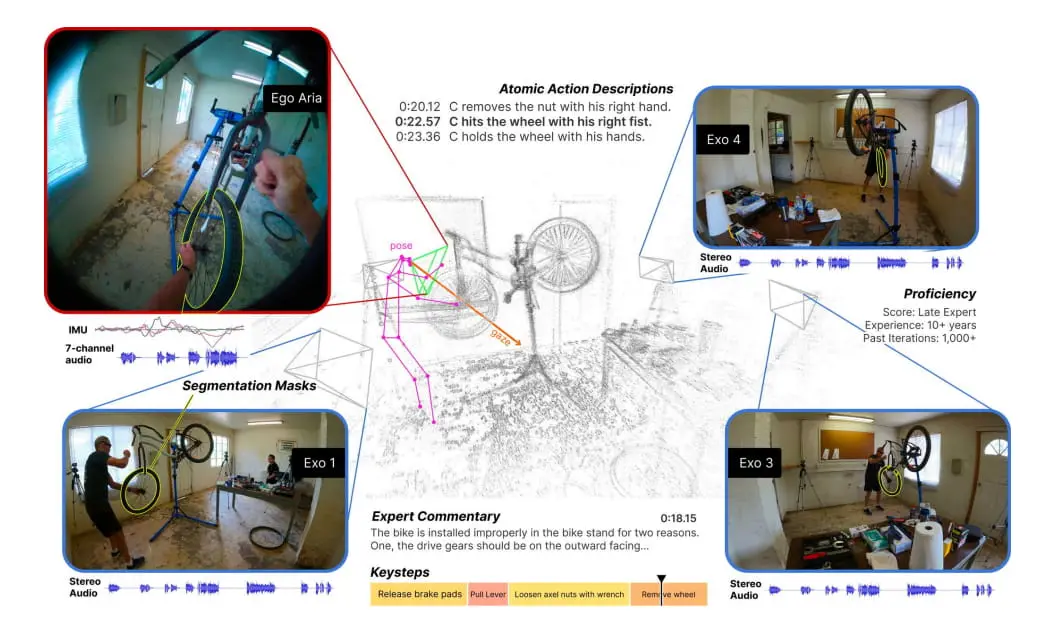
- 8、Meta发布多模态数据集Ego-Exo4D
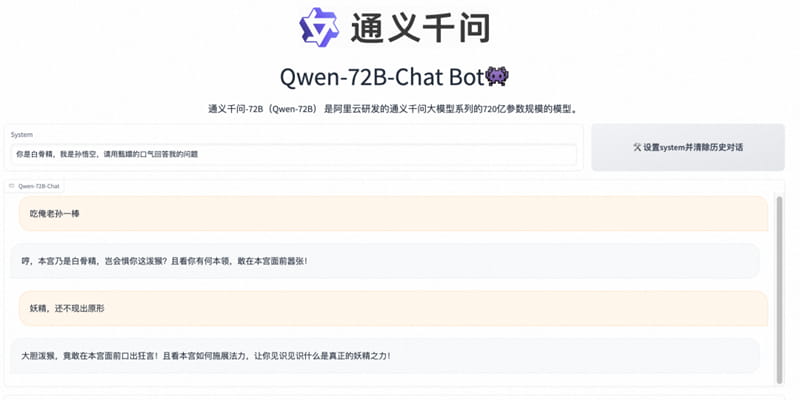
- 9、阿里云通义千问开源720亿参数大模型
- 10、阿里推出AI动画生成框架 从静态图像生成动画
- 11、Adobe等推出DMD方法 生图速度提升30倍
- [t-info icon='']AI·新创[/t-info]
[t-success icon='']AI·快讯[/t-success]
1、OpenAI 仍坚持售股计划,并将多给员工一个月时间考虑是否参与
据多位知情人士透露,人工智能初创公司 OpenAI 坚持让员工通过“要约收购”出售公司股份的计划,并多给他们 1 个月的时间来考虑是否出售所持股票。知情人士曾在 10 月份表示,OpenAI 始终在就出售员工持股事宜与投资者进行谈判,这笔交易对该公司的估值为 860 亿美元。但是,本月早些时候,在首席执行官萨姆・阿尔特曼(Sam Altman)先被解雇后又迅速复职的动荡中,人们担心售股可能不会按计划进行。(来源:IT之家)
2、昆仑万维发布“天工SkyAgents”平台
12月1日,昆仑万维正式发布「天工SkyAgents」平台,助力大模型走入千家万户。「天工SkyAgents」是国内领先的AI Agents开发平台,基于昆仑万维「天工大模型」打造,具备从感知到决策,从决策到执行的自主学习和独立思考能力。用户可以通过自然语言构建自己的单个或多个“私人助理”。并且将不同任务模块化,通过操作系统模块的方式,实现执行包括问题预设、指定回复、知识库创建与检索、意图识别、文本提取、http请求等任务。(来源:雷锋网)
内测申请地址:https://agentspro.cn
3、亚马逊推出 Titan 系列 AI 模型:可生成图片及文本、号称兼顾价格和性能
亚马逊昨天在 re: Invent 大会中,公布了三款“Titan”系列生成式 AI 模型,其中包含亚马逊旗下首个图像生成模型“Titan Image Generator”、文字生成模型“Amazon Titan Text Express”及“Titan Text Lite”。据悉,Titan Image Generator 是亚马逊自行开发的最新 Titan 家族模型,号称能够赶上 OpenAI、谷歌、微软等竞争者。该模型具备“图片编辑”及“隐藏水印”等功能,允许用户以英语输入提示词句,以生成“专业等级”的图像。亚马逊表示,Titan Image Generator 以高品质且多样化的数据训练而成,因此可以生成精准、拟真、多元的图片。(来源:IT之家)

4、DeepMind 推出 AI 工具 GNoME,号称已发现 220 万种新晶体材料
谷歌旗下 DeepMind 日前在《自然》期刊上展示了自家 AI 工具 GNoME,并介绍了 AI 在材料科学上的相关应用,据悉,DeepMind 使用 GNoME 发现了 220 万种新晶体,其中有 38 万种晶体属于稳定材料,可以在实验室制造,有望应用在电池或是超导体等方面。DeepMind 的新工具 GNoME,据称突破了此前的各种计算方法,能够准确预测一系列稳定的晶体结构,并从中生成了 220 万种材料,DeepMind 声称,如果仅凭借人力计算出这些材料,需要花费 800 年。(来源:IT之家)
5、未来有望抽管血就可诊断和预测老年痴呆,科学家研发出新 AI 算法
在湖南师范大学信息科学与工程学院教授毕夏安的带领下,脑科学与人工智能团队创新尝试,开发出可诊断阿尔茨海默病(AD,又称老年痴呆症)的 AI 算法。该团队深入分析大脑影像和基因数据,将其作为 AD 的宏观视图与微观视图,提出一种用于疾病分类与风险预测的深度学习算法,可精准生成大脑功能网络视图。(来源:IT之家)

6、Meta开源实时翻译系列模型Seamless
今日,Meta推出实时翻译系统Seamless。为了构建Seamless,Meta开发了一种用于保留语音到语音翻译中表达能力的模型SeamlessExpressive,以及一个流式翻译模型SeamlessStreaming,可以以几乎不到两秒的延迟提供最先进的结果。所有模型均基于Meta在8月发布的基础模型SeamlessM4T v2构建。据介绍,与之前在表达性语音研究方面的努力相比,SeamlessExpressive解决了韵律中某些尚未开发的方面,例如语速和节奏停顿,同时还保留了情感和风格。该模型目前在英语、西班牙语、德语、法语、意大利语和中文之间的语音到语音翻译中保留了这些元素。SeamlessStreaming支持近100种输入和输出语言的自动语音识别和语音到文本翻译,以及近100种输入语言和36种输出语言的语音到语音翻译。Meta开源了全部四种模型,以便研究人员在此基础上进一步研究。
开源地址:https://github.com/facebookresearch/seamless_communication

7、Meta推出音频生成模型Audiobox
今日,Meta推出音频生成模型Audiobox,该模型可以结合使用语音输入和自然语言文本提示来生成语音和音效,从而可以轻松地为各种用例创建自定义音频。Meta称,据其所知,Audiobox是第一个支持语音和文本双输入以进行自由语音重新设计的模型。Meta将在接下来的几周内开放基于Audiobox的应用程序,以及展示Audiobox功能的交互式演示。
8、Meta发布多模态数据集Ego-Exo4D
今日,Meta推出一个基础数据集和基准套件Ego-Exo4D,用于支持视频学习和多模态感知的研究。据介绍,Ego-Exo4D是Meta的FAIR(基础人工智能研究)、Aria项目和15所大学合作伙伴历时两年的研究成果。Ego-Exo4D的核心是同时捕捉参与者佩戴摄像头的第一人称(自我中心)视角和周围摄像头的多个第三人称(非自我中心)视角。两个视角相互补充,自我中心的视角揭示了参与者的视听感知,而非自我中心的视角则揭示了周围场景和上下文。研究者将在本月开源数据(包括超过1400小时的视频)和用于新基准测试任务的注释。
9、阿里云通义千问开源720亿参数大模型
今日,阿里云在京举办通义千问发布会,开源通义千问720亿参数模型Qwen-72B。据介绍,Qwen-72B在10个权威基准测评创下开源模型最优成绩,性能超越开源标杆Llama 2-70B和大部分商用闭源模型,可适配企业级、科研级的高性能应用。通义千问当天还开源了18亿参数模型Qwen-1.8B和音频大模型Qwen-Audio,在业界率先实现“全尺寸、全模态”开源。
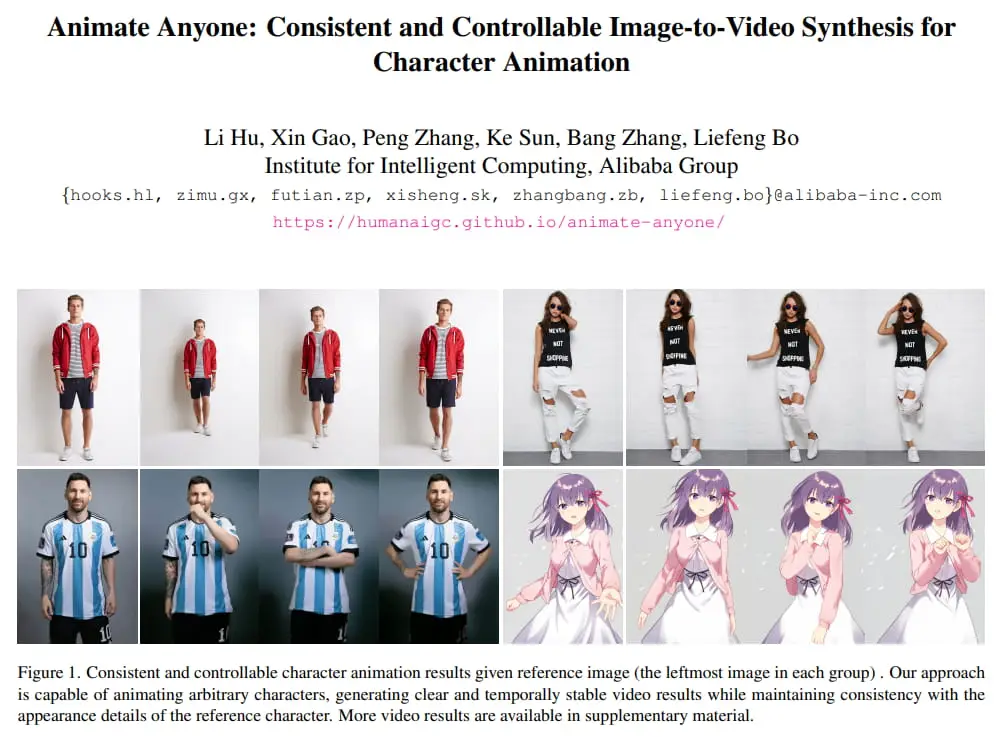
10、阿里推出AI动画生成框架 从静态图像生成动画
11月29日,来自阿里的研究团队发布论文,利用扩散模型的能力,提出了一个专门针对角色动画的新框架Animate Anyone,可从静态图像AI生成动态视频,从而将任意角色动画化。为了保持参考图像中复杂外观特征的一致性,作者改进了ReferenceNet算法,通过空间注意力融合详细特征。为了确保可控性和连贯性,作者引入了一个高效的姿势指导器来指导角色的动作,并采用了一种有效的时间建模方法,确保视频帧之间的平滑过渡。
11、Adobe等推出DMD方法 生图速度提升30倍
今日,Adobe和麻省理工学院的研究人员共同发布论文,介绍一种分布匹配蒸馏(Distribution Matching Distillation,DMD)方法,可在速度提升30倍的情况下生成与Stable Diffusion v1.5相当的图像质量。论文的核心思想是训练两个扩散模型,不仅估计目标真实分布的评分函数,还估计伪造分布的评分函数。方法类似于生成对抗网络(GANs),即通过同时训练评论家和生成器来最小化真实分布和伪造分布之间的差异,但不同之处在于训练不涉及可能导致不稳定的对抗博弈,并且评论家模型可以充分利用预训练扩散模型的权重。

[t-info icon='']AI·新创[/t-info]
1、「海纳AI」完成数千万元A轮融资,为企业提供AI面试服务
「海纳AI」是北京群星闪耀科技有限公司旗下的人才招聘垂直领域AI产品,最早于2019年推出,专攻AI面试服务,帮助企业借助AI技术完成招聘面试环节。海纳AI的AI面试官(数字人)可以7X24小时自动面试候选人,代替HR进行介绍和提问,候选人只需在手机上录制短视频回答,面试过程省时省力。面试结束后,AI自动给候选人打分,企业在后台就能看到所有候选人的面试成绩。此外,AI面试支持数十万人同时面试,最大限度缩短招聘周期。(来源:36氪)
2、用AI推进多肽药物研发,「动肽医药」获800万美元种子轮融资
动肽医药是一家基于高度整合的计算设计-自动化合成平台的多肽药物研发公司,旨在构建下一代多肽药物发现引擎,试图在以往难以成药的靶点和疾病领域,加速发现过程、并提高多肽候选药物质量。公司在中国上海和美国波士顿均设有运营机构。据Blanchard博士介绍,目前公司已构建了一个整合性平台——能通过基于物理计算的方法,虚拟迭代数百万多肽序列,预测其结合亲和力和其他成药性质,并结合实验数据发现和优化候选药物。据悉,该方法预计将加速多肽药物的发现速度,降低研发成本,并提高候选药物的质量。通过本次融资,公司将推进其领先项目进入临床阶段,并继续在肿瘤学、自身免疫类疾病和代谢疾病领域构建其临床前项目组合。 (来源:36氪)