随着边缘和移动设备对AI模型的依赖日益增加,显著的挑战也随之而来。在计算效率、模型规模和多语言能力之间取得平衡仍然是一个持续的难题。传统的大型语言模型(LLMs)虽然功能强大,但通常需要大量资源,这使得它们不太适合智能手机或物联网设备等边缘应用。此外,在不增加硬件负担的情况下提供强大的多语言性能也一直难以实现。这些挑战凸显了需要为边缘环境设计高效且多功能的LLMs。
Kyutai Labs发布了Helium-1预览版,这是一款专为边缘和移动环境设计的20亿参数多语言基础LLM。与许多前代模型不同,Helium-1旨在保持紧凑高效设计的同时,性能与Qwen 2.5(1.5B)、Gemma 2B和Llama 3B等模型相当甚至更好。Helium-1以宽松的CC-BY许可证发布,旨在解决可访问性和实际部署中的关键问题。
基于Transformer架构,Helium-1对多语言能力的关注使其在需要语言多样性的应用中尤为有价值。该模型的边缘优化设计确保开发者可以在计算资源有限的环境中部署它,而不会影响性能。这些特性使Helium-1成为面向全球多样化用例的可访问AI的重要一步。
关键技术特性与优势
Helium-1预览版集成了多项技术特性,使其具备出色的性能:
- 平衡的架构:凭借20亿参数,Helium-1在计算效率和能力之间取得了平衡。它利用从70亿参数模型中进行的分词级蒸馏,确保输出质量的同时最小化复杂性。
- 广泛的训练数据:Helium-1在2.5万亿个token上进行了训练,为其理解和生成多种语言提供了坚实的基础。其4096个token的上下文长度支持有效处理较长的文本输入。
- 边缘优化:专为资源受限的环境设计,Helium-1最大限度地减少了延迟和内存使用,使其成为移动和物联网应用的理想选择。
- 开放访问:CC-BY许可证确保开发者和研究人员可以自由地调整和构建该模型,鼓励进一步创新。
性能与观察
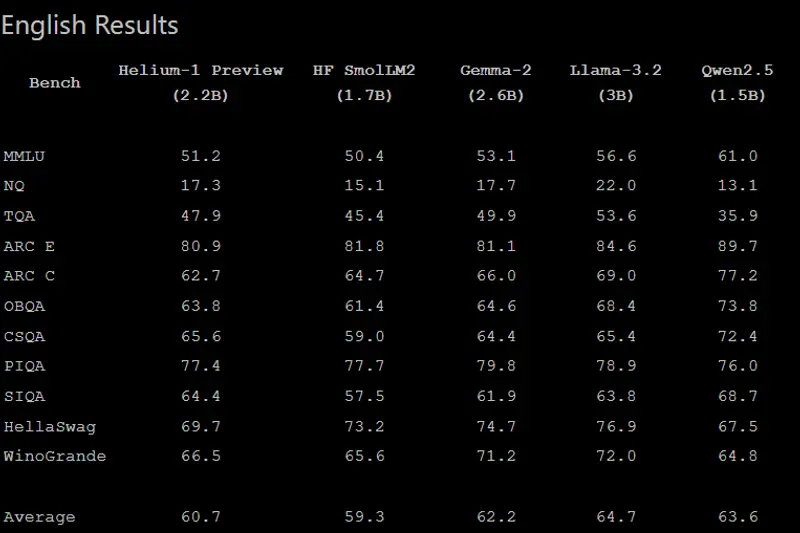
Helium-1的初步评估显示,其在多语言基准测试中表现强劲,通常优于或匹配Qwen 2.5(1.5B)、Gemma 2B和Llama 3B等模型。这些结果突显了其训练策略和优化的有效性。
尽管规模相对较小,Helium-1展现了令人印象深刻的多样性。它能够准确处理复杂查询,并生成连贯且与上下文相关的响应,使其适用于对话式AI、实时翻译和移动内容摘要等应用。