在AI领域,OpenAI的o1模型及其类似模型(如Qwen和DeepSeek)因其能够模拟人类长时间思考的能力而备受瞩目。这些模型通过扩展链式思维(CoT)过程,探索多种策略来增强问题解决能力。然而,如何在测试过程中智能且高效地扩展计算资源仍然是一个关键问题。腾讯AI实验室和上海交通大学的研究人员首次全面研究了o1类模型中普遍存在的过度思考问题,并提出了几种策略来缓解这一问题。
过度思考问题的观察与分析
解决方案分布
我们通过对三个测试集(ASDIV、GSM8K和MATH500)的分析,发现o1类模型在大多数情况下会产生2到4个解决方案。对于较简单的测试集,模型倾向于生成更多的解决方案。
对准确性的效率
我们引入了一个结果效率指标,用于评估后续解决方案对准确性改进的贡献。结果表明,超过92%的情况下,第一个解决方案已经给出了正确答案,后续解决方案对准确性改进的贡献微乎其微。
思维多样性的效率
我们还引入了一个过程效率指标,用于评估后续解决方案对解决方案多样性的贡献。结果显示,后续解决方案往往重复前面的解决方案,缺乏多样性。
实验结果
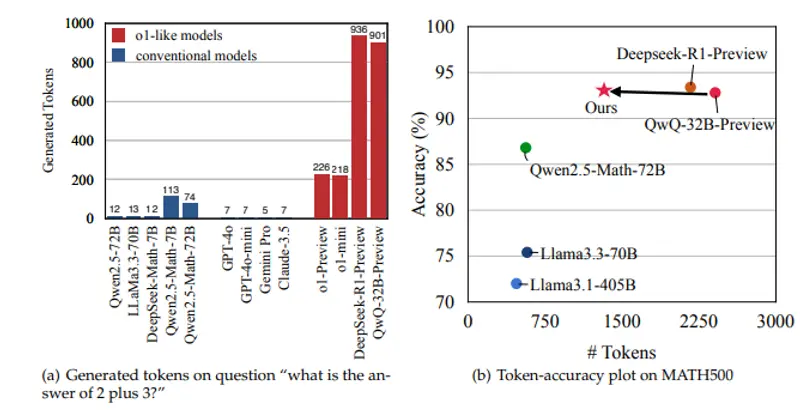
表1展示了不同模型的效率结果。与传统的LLM相比,o1类模型生成的响应更长,改进准确性和解决方案多样性的效率较低。图7进一步显示了在不同难度级别的MATH500测试集上的详细效率结果,表明o1类模型在简单问题上尤其存在过度思考问题。
缓解过度思考的策略
长度偏好优化
我们尝试了几种自训练方法来提高模型的效率,包括监督微调(SFT)、直接偏好优化(DPO)、推理偏好优化(RPO)和简单偏好优化(SimPO)。结果表明,SimPO在减少生成的标记数方面表现最佳。
简化响应以进一步提高效率
我们提出了三种简化策略来进一步提高效率:
- 第一正确解决方案(FCS):保留第一个到达正确答案的解决方案。
- FCS+反思:在保留第一个正确解决方案的基础上,增加第二个正确解决方案以保持模型的长链思维能力。
- 贪婪多样化解决方案(GDS):选择提供新视角的解决方案,并在第二个解决方案不重复第一个的情况下增加更多解决方案。
表3显示了不同简化策略的统计数据,结果表明“FCS+反思”在准确性和过程效率之间取得了最佳平衡。
挑战性测试集上的结果
为了验证我们的方法是否削弱了o1类模型处理复杂问题的能力,我们在GPQA和AIME等更具挑战性的测试集上进行了验证。结果表明,我们的方法在保持模型性能的同时减少了标记数,展示了方法的鲁棒性和泛化能力。
结论
本文首次全面研究了o1类模型中的过度思考问题,并提出了几种策略来缓解这一问题。我们的自训练方法有效地减少了不必要的计算,同时保持了模型性能。未来的研究方向包括探索动态调整计算资源的自适应策略和细化效率指标以促进更广泛的模型泛化。
限制
- 模型覆盖:我们的分析仅基于两个模型(QwQ 32B-Preview和DeepSeek-R1-Preview),并且我们的效率增强方法仅在QwQ-32B-Preview上进行了验证。
- 多样性测量:我们使用GPT-4o进行解决方案聚类,这既昂贵又难以复制。未来我们将使用更多的开源LLM进行多样性评估。
- PRM12K训练数据的偏差:我们的验证仅依赖于广泛使用的PRM12K数据集,可能影响方法的鲁棒性。我们计划探索更大的数据集来解决这个问题。
尽管本文没有完全解决o1类模型中的过度思考问题,但为未来的研究奠定了基础。