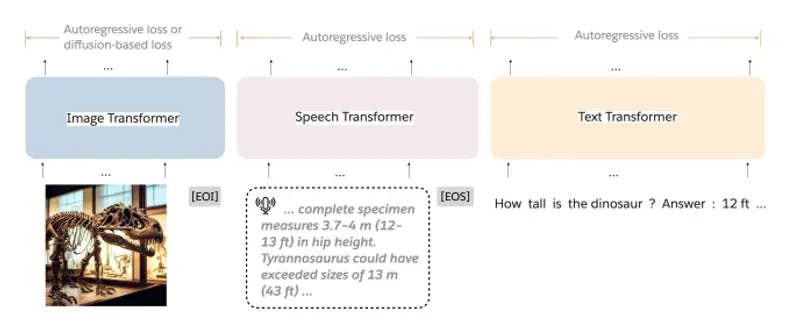
大语言模型(LLMs)的发展已经扩展到多模态系统,这些系统能够在统一的框架内处理文本、图像和语音。与仅处理文本的LLMs相比,训练这些多模态模型需要显著更大的数据集和计算资源。为了应对这些扩展挑战,Meta和斯坦福大学计算机科学系的研究人员引入了Mixture-of-Transformers(MoT),这是一种稀疏的多模态Transformer架构,显著降低了预训练的计算成本。
这种架构旨在处理文本、图像和语音等多种数据类型,并且在统一的框架内进行训练。MoT通过引入模型稀疏性,显著降低了预训练的计算成本,同时保持了模型的性能。
例如,在“Chameleon”设置中,MoT在自回归文本和图像生成任务中,仅使用密集基线模型55.8%的浮点运算(FLOPs)就匹配了其性能。当扩展到包括语音这一第三模态时,MoT在仅使用密集基线模型37.2%的FLOPs的情况下,就达到了与之相当的语音性能。
MoT 架构
MoT 通过模态解耦模型的非嵌入参数——包括前馈网络、注意力矩阵和层归一化——实现了模态特定的处理,并在整个输入序列上进行全局自注意力。具体来说:
- 模态解耦:
- 前馈网络:每个模态(文本、图像、语音)都有自己的前馈网络,以处理模态特定的特征。
- 注意力矩阵:每个模态有自己的注意力矩阵,以捕获模态内部的依赖关系。
- 层归一化:每个模态有自己的层归一化参数,以适应模态特定的分布。
- 全局自注意力:
- 跨模态交互:在整个输入序列上进行全局自注意力,以捕捉不同模态之间的交互。
主要功能: MoT的主要功能是提供一个高效的多模态学习架构,它可以处理交错的多模态序列(如文本、图像和语音),并动态应用特定于模态的参数,包括前馈网络、注意力投影矩阵和层归一化。
主要特点:
- 模态特定的参数解耦: MoT将非嵌入参数按模态解耦,使得每个模态都有自己的参数集,同时保持全局自注意力机制。
- 计算效率: MoT在保持性能的同时,显著减少了模型的计算需求。
- 可扩展性: MoT在不同模型规模下都能保持效率和性能,从小型到大型模型。
- 多模态处理: MoT能够处理包括文本、图像和语音在内的多种模态数据。
工作原理:
MoT的工作原理基于Transformer架构,但对所有非嵌入参数(如前馈网络、注意力矩阵和层归一化)进行了模态特定的解耦。这意味着每个模态都有自己的参数集,但它们仍然可以在全局自注意力层中交互。这样,MoT可以针对每个模态的特点进行优化,同时保持跨模态的联系。
实验结果
研究人员在多种设置和模型规模上评估了MoT,结果表明:
- Chameleon 7B 设置:
- 任务:自回归文本和图像生成。
- 性能:MoT仅使用55.8%的FLOPs就达到了密集基线的性能。
- 扩展到语音:
- 任务:包括语音在内的多模态生成。
- 性能:MoT仅使用37.2%的FLOPs就达到了与密集基线相当的语音性能。
- Transfusion 设置:
- 任务:文本和图像以不同的目标进行训练。
- 性能:
- 一个7B的MoT模型在三分之一的FLOPs下达到了密集基线的图像模态性能。
- 一个760M的MoT模型在关键图像生成指标上优于一个1.4B的密集基线。
系统分析
系统分析进一步突显了MoT的实际效益:
- 图像质量:在47.2%的挂钟时间内实现了密集基线的图像质量。
- 文本质量:在75.6%的挂钟时间内实现了密集基线的文本质量(在配备NVIDIA A100 GPU的AWS p4de.24xlarge实例上测量)。
应用前景
MoT 的提出为多模态大语言模型的训练提供了一种高效的解决方案,具有广泛的应用前景:
- 内容创作:电影和动画制作中,创作者可以使用MoT生成高质量的文本、图像和语音内容。
- 虚拟现实和增强现实:生成逼真的3D和4D场景,提升虚拟现实和增强现实的沉浸感。
- 自动驾驶和机器人:生成逼真的3D环境,用于自动驾驶和机器人的训练和测试。