
AI视频生成领域已经涌现出多家明星创业公司,之前小编已经介绍过Runway旗下AI视频生成工具Gen2、「Morph Studio 」和「Moonvalley」,在AI绘画领域大红大紫的公司Stability AI在接连推出 Stable Diffusion、Stable Audio和Stable LM后,也开始在AI视频生成领域发力,在今天正式推出视频生成模型Stable Video Diffusion,Stable Video Diffusion 由两个模型组成的 ——SVD 和 SVD-XT。SVD 可以将静态图片转化为 14 帧的 576×1024 的视频。SVD-XT 使用相同的架构,但将帧数提高到 24。两者都能以每秒 3 到 30 帧的速度生成视频。
开源地址:https://github.com/Stability-AI/generative-models
模型地址:https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt
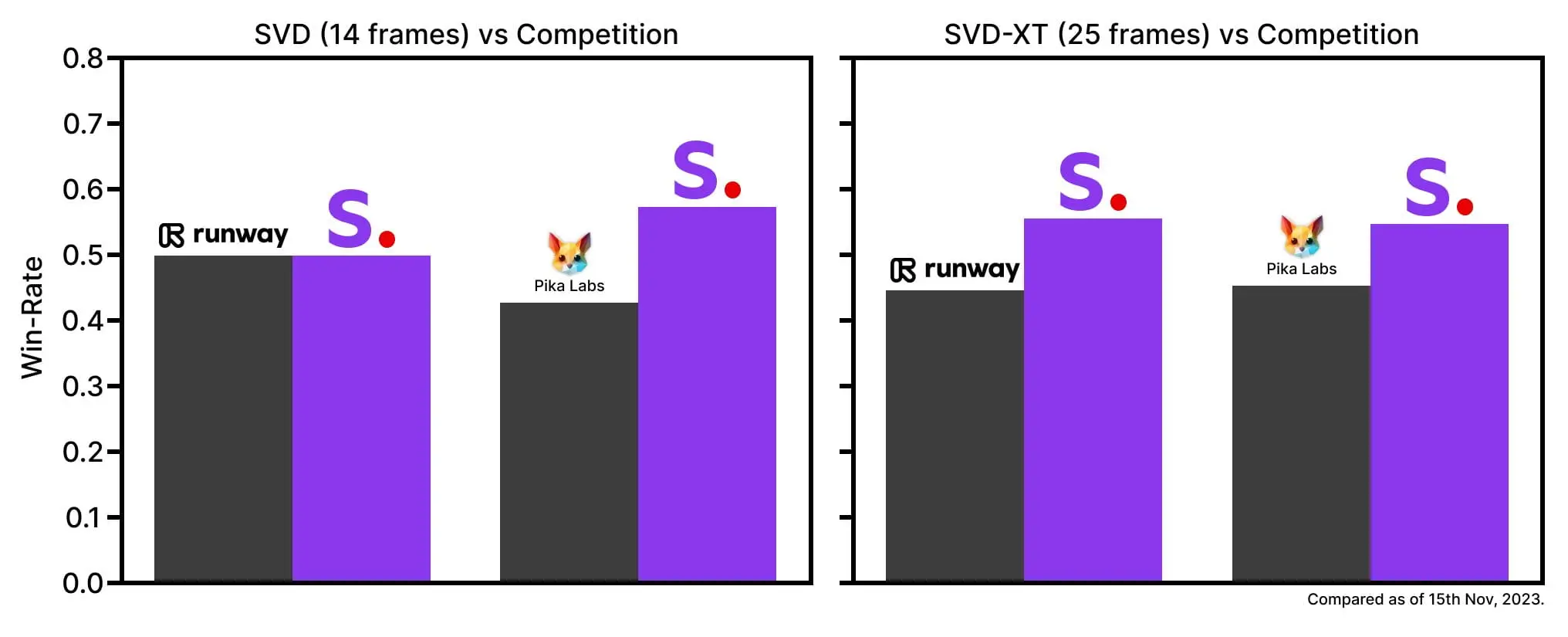
Stable Video Diffusion源代码采用 MIT License 发布在 GitHub 上,模型发布在 Hugging Face 上。 Stable Video Diffusion 基于 Stable Diffusion,有两种输出形式,能以每秒 3-30 帧的定制帧速生成 14 和 25 帧。 Stability AI 称其模型的表现好于私有模型。
根据 Stability AI 随 Stable Video Diffusion 一起发布的一篇白皮书,SVD 和 SVD-XT 最初是在一个包含数百万视频的数据集上进行训练的,然后在一个规模较小的数据集上进行了“微调”,这个数据集只有几十万到一百万左右的视频片段。这些视频的来源并不十分清楚,白皮书暗示许多是来自公开的研究数据集,所以无法判断是否有任何版权问题。
https://www.bilibili.com/video/BV1iz4y1c79z
不过经过不少网友的测试,此模型至少需要带有20G显存的显卡才能勉强运行,还有很多网友说至少40G显存显卡才能完全运行,所以大家还是等待后续优化或者微调模型出现,现在就看哪家Stable Diffusion UI 最先支持此模型了,大家期待吧!