文章目录[隐藏]
- [t-success icon='']AI·快讯[/t-success]
- 1、快手自研文生图大模型“可图”已开启内测
- 2、微软AI团队意外泄露38TB数据,包含3万多条团队内部消息
- 3、英国公布AI监管原则:开发者要为输出内容负责
- 4、微软 Win11 画图有望引入 AI 生成图像功能,基于 DALL-E
- 6、复旦NLP团队发布80页大模型Agent综述
- 7、新加坡华人团队开源通用多模态大模型NExT-GPT
- 8、万兴科技将推视频创意多媒体大模型“天幕”
- 9、微软开源AI新框架EvoDiff,使模型可设计自然界所有蛋白质
- 10、Google轻量化脸部编辑GAN模型,低阶手机也可即时生成高品质输出
- 11、英伟达CEO:希望加强与越南在半导体、AI等领域合作,或在越建厂
- 12、百度发布“产业级”医疗大模型“灵医大模型”
- 13、巨量引擎:推出智能短视频脚本工具
- 14、火山引擎数智平台发布AI助手
- 15、谷歌 Bard 人工智能聊天机器人升级:已支持插件功能
- 16、GPT-5 来了?OpenAI 被曝加急训练多模态大模型 Gobi,一举狙杀谷歌 Gemini!
[t-success icon='']AI·快讯[/t-success]
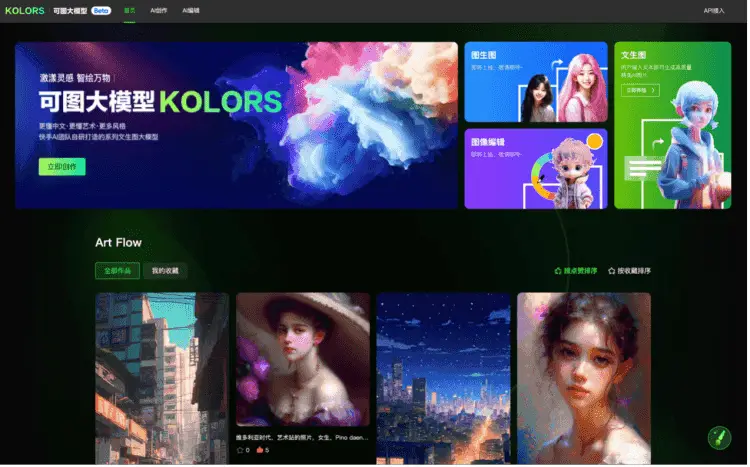
1、快手自研文生图大模型“可图”已开启内测
近日,快手自研文生图大模型“可图”(Kolors)已开启内测。可图大模型能够基于开放式文本生成绘画作品。据了解,此前快手在站内短视频评论内测的AI文生图功能“AI玩评”,正是依托于“可图”的图像生成能力实现。这也是快手AI团队在大语言模型“快意”之后,再次公布其在AIGC领域的最新突破和布局。
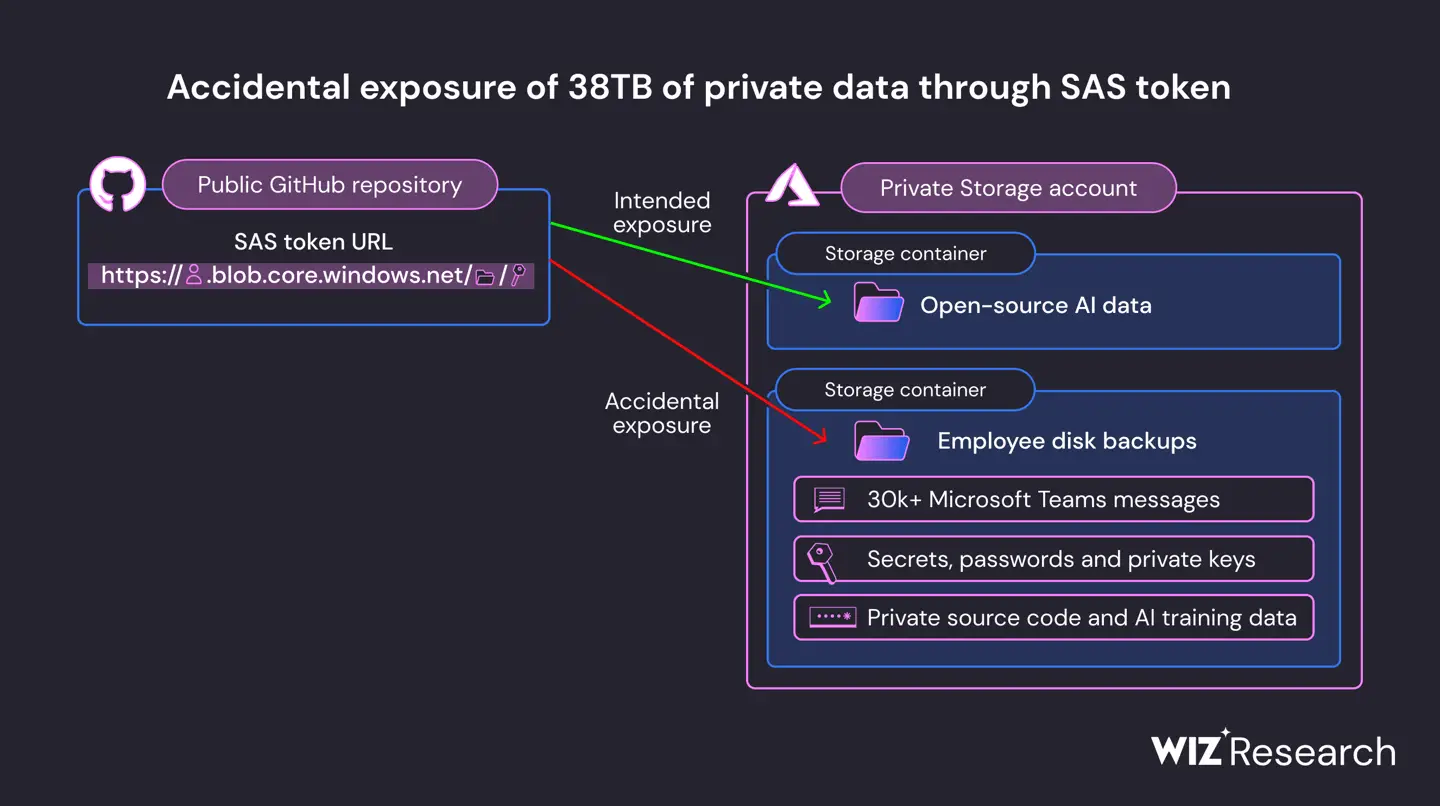
2、微软AI团队意外泄露38TB数据,包含3万多条团队内部消息
云安全公司Wiz发布报告称,微软人工智能研究团队在Github发布开源训练数据时意外泄露了38TB的额外私人数据,包括密钥、两名员工工作站的磁盘备份和3万多条微软Teams内部消息。这些是由一个错误配置的SAS令牌引起。Wiz认为,这一案例提醒工程师要充分考虑组织人工智能研究所需的安全措施。(来源:IT之家)
3、英国公布AI监管原则:开发者要为输出内容负责
据报道,英国反垄断监管机构“竞争与市场管理局”(CMA)今日提出了管理AI模式的新标准,涵盖问责、访问和透明度等事宜,以促进这项技术的健康发展。早在今年5月份,英国CMA就开始研究ChatGPT等生成式人工智能应用的影响,以确保这项技术被用于造福企业和消费者。(来源:新浪科技)
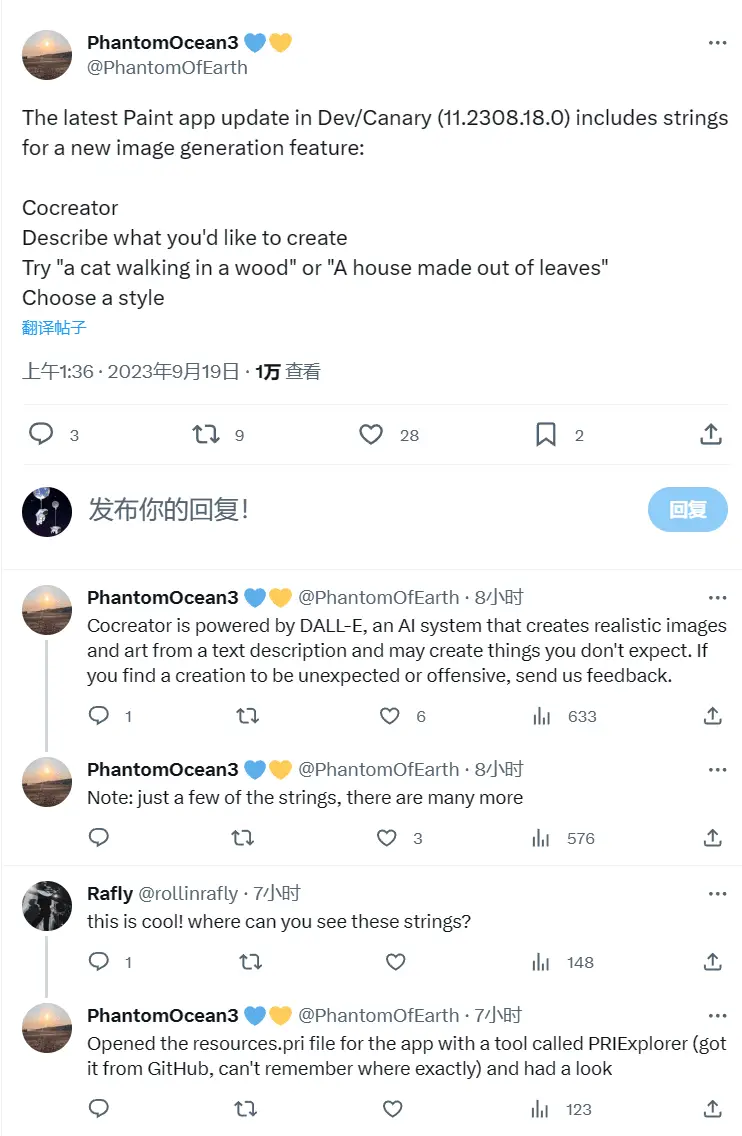
4、微软 Win11 画图有望引入 AI 生成图像功能,基于 DALL-E
微软日前面向 Windows 测试人员推出了新版画图应用(Dev / Canary 版本 11.2308.18.0),为大家带来了 Photoshop 的核心功能之一 —— 图层。除此之外,爆料人 PhantomOcean3 从新版画图的文件中发现,有一段用于新图像生成功能的字符串,该功能被命名为“Cocreator”。PhantomOcean3 表示,该功能将基于 OpenAI 的 DALL-E,预计会类似必应聊天中使用的 Bing Image Creator 服务。
5、淘宝问问 AI 助手测试版上线:无需申请即可体验,具有导购功能
淘宝 AI 大模型“淘宝问问”现已上线测试,用户将 App 升级到最新版(苹果手机更新到 iOS14 以上系统),无需申请即可体验。据淘宝官方介绍,淘宝问问是淘宝 App 在原搜索功能上对电商搜索导购方式进行迭代的创新尝试,旨在结合用户输入,通过深度合成算法为用户提供更符合消费习惯的商品和内容。用户在淘宝 App 搜索框输入“淘宝问问”即可跳转到相关页面,进入该页面之后在搜索框内输入产品名称,即可看到相关产品的视频和文字介绍。此外,推荐产品的购买链接也会出现在文字介绍之下。
6、复旦NLP团队发布80页大模型Agent综述
据机器之心报道,近期,复旦大学自然语言处理团队(FudanNLP)推出LLM-based Agents综述论文,全文长达86页,共有600余篇参考文献。作者们从AI Agent的历史出发,全面梳理了基于大型语言模型的智能代理现状,包括:LLM-based Agent的背景、构成、应用场景以及备受关注的代理社会。同时,作者们探讨了Agent相关的前瞻开放问题,对于相关领域的未来发展趋势具有重要价值。
论文链接:https://arxiv.org/pdf/2309.07864.pdf
LLM-based Agent论文列表:https://github.com/WooooDyy/LLM-Agent-Paper-List

7、新加坡华人团队开源通用多模态大模型NExT-GPT
据新智元报道,上周,新加坡国立大学NExT++实验室的华人团队正式开源了一款“大一统”通用多模态大模型NExT-GPT,支持任意模态输入到任意模态输出,并上线了Demo系统。据介绍,NExT-GPT能够准确理解用户所输入的各类组合模态下的内容,并准确灵活地返回用户所要求的甚至隐含的多模态内容,从而输出图像、视频以及声音。

8、万兴科技将推视频创意多媒体大模型“天幕”
据财联社报道,9月15日,AIGC软件公司万兴科技宣布即将推出百亿级参数“天幕”多媒体大模型。据介绍,“天幕”是以视频创意应用为核心的多媒体大模型。发布会上,万兴科技还与湘江实验室达成战略合作,双方将共同构建产学研用联盟创新体系,推进人才、技术与应用成果转化的合作。
9、微软开源AI新框架EvoDiff,使模型可设计自然界所有蛋白质
微软已将通用扩散模型框架EvoDiff开源,结合了能够处理大量且多元资料的特性,以及扩散模型特殊的控制能力,在序列空间中能以可控制的方法生成蛋白质。使用EvoDiff所训练的模型,能够生成多样化且结构合理的蛋白质,特别的是,EvoDiff模型还可以生成以结构为基础的模型所无法生成的模型,这代表使用序列为基础的方法具有通用性。
论文地址:https://www.biorxiv.org/content/10.1101/2023.09.11.556673v1
10、Google轻量化脸部编辑GAN模型,低阶手机也可即时生成高品质输出
Google针对生成对抗网路(Generative Adversarial Network,GAN)的高运算复杂度提出解决方案,将原本需要在伺服器执行的脸部编辑模型轻量化,推出可在手机上运作的少样本脸部风格模型MediaPipe FaceStylizer,提供高品质脸部图片生成,并且透过MediaPipe平台公开,让用户能够自订部署到行动装置上。(来源)
模型地址:https://blog.research.google/2023/09/mediapipe-facestylizer-on-device-real.html

11、英伟达CEO:希望加强与越南在半导体、AI等领域合作,或在越建厂
据越南政府网站,当地时间9月18日,越南总理范明政在美国加州硅谷拜访英伟达、Meta和新思科技等多家美国科技公司。范明政与英伟达CEO黄仁勋讨论了全球人工智能发展趋势以及该集团与越南方面开展合作的潜力,寻求为越南正在制定的国家半导体战略提供建议。范明政邀请黄仁勋尽快赴越南访问和开展工作,希望英伟达尽快在越南设立生产工厂,以越南为东南亚基地。根据声明,黄仁勋同意范明政的建议,希望加强与越南在半导体、信息技术、AI等领域合作,预计越南“完全可成为公司在东南亚的生产基地”。
12、百度发布“产业级”医疗大模型“灵医大模型”
百度正式发布国内首个“产业级”医疗大模型——灵医大模型。目前,灵医大模型已与固生堂、零假设等达成合作,并已定向向公立医院、药械企业、互联网医院平台、连锁药房等200多家医疗机构开放体验。
13、巨量引擎:推出智能短视频脚本工具
近日,巨量引擎推出一款智能短视频脚本工具,免费开放给抖音商家使用。据介绍,该工具选定行业优秀素材后,系统将为商家智能分析视频,锁定高光帧和拆解黄金公式,仅需20秒即可根据内容公式或自定义功能,自动生成爆款带货短视频脚本。商家使用智能短视频脚本工具GMV提升58%。
14、火山引擎数智平台发布AI助手
9月19日,火山引擎在其举办的“V-Tech数据驱动科技峰会”上宣布,火山引擎数智平台VeDI推出“AI助手”,通过接入人工智能大模型,帮助企业提升数据处理和查询分析的效率。目前,VeDI相关数据产品已启动邀测。
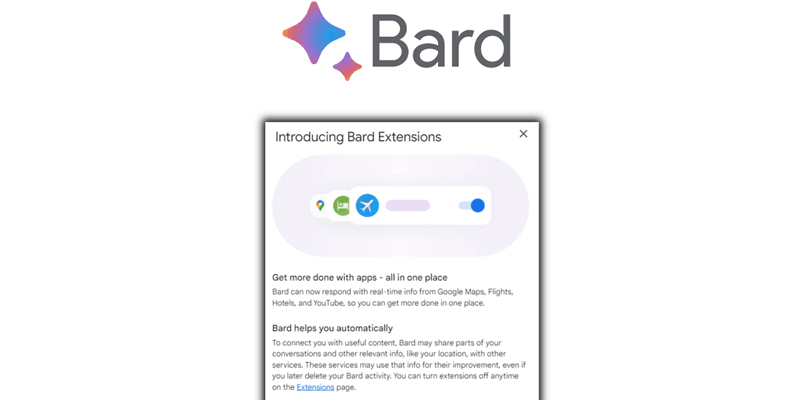
15、谷歌 Bard 人工智能聊天机器人升级:已支持插件功能
今天,人工智能聊天机器人谷歌 Bard 发布了最新的更新,增加了对谷歌应用的插件支持,包括 Gmail、Docs、Drive 等。谷歌表示,这是 Bard 迄今为止功能最强大的版本,可以在全球各种语言和国家中提高协作效率。谷歌应用的插件可以让 Bard 访问和使用来自 Maps、YouTube、Hotels 和 Flights 等应用的实时信息,并且可以随时关闭。用户只需在 Bard 的界面右上角点击插件图标,或者在提示框中输入“@”加上插件的名称,就可以快速选择一个插件。例如,用户可以输入“@Maps”来让 Bard 显示地图信息,或者输入“@YouTube”来让 Bard 播放视频。

16、GPT-5 来了?OpenAI 被曝加急训练多模态大模型 Gobi,一举狙杀谷歌 Gemini!
据外媒 The Information 爆料,一款名为 Gobi 的全新多模态大模型,已经在紧锣密鼓地筹备了。OpenAI 计划,在 Gemini 发布之前就推出多模态 LLM,彻底击败谷歌。其实,在 3 月份推出 GPT-4 多模态功能的预览后,OpenAI 已经向一家名为 Be My Eyes 的公司推出了这项功能,但并没有向其他公司提供。从名字就可以看出来,这家公司在研发让盲人或视力不佳人群看得更清楚的技术。(来源:IT之家)