文章目录[隐藏]
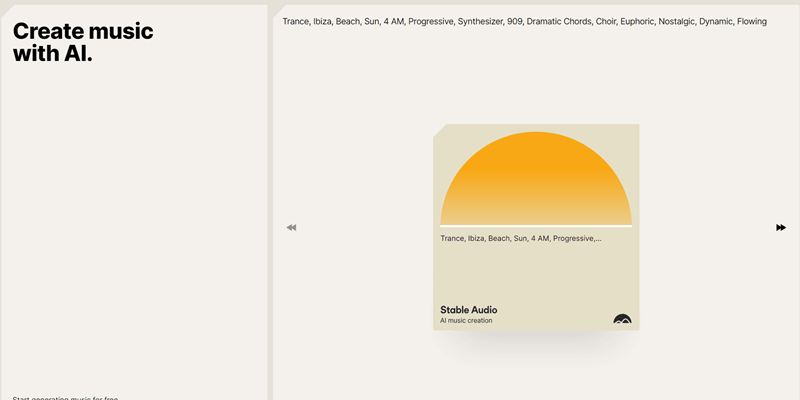
Stability AI之前已经推出了文字生成图像模型Stable Diffusion、大语言模型StableLM,官方又在本周推出了文字生成音乐模型Stable Audio,可以基于用户输入的文本内容,自动生成音乐或者音频。与之前谷歌的MusicLM与Meta的音乐生成模型MusicGen相似,今天就一起来看看吧!
[t-success icon='']Stable Audio[/t-success]
Stable Audio是由Stability AI旗下生成式声音研究实验室Harmonai开发,利用由AudioSparx所提供的80万个音频文件组成的数据集进行训练,涵盖音乐、音效、各种乐器,以及相对应的文本元数据等,总长超过1.9万个小时。Stability AI表示一般的声音扩散模型通常是在较长音频文件中随机裁剪的声音区块进行训练,可能导致所生成的音乐缺乏头尾,但Stable Audio架构同时基于文字,以及音频文件的持续及开始时间,而让该模型得以控制所生成声音的内容与长度。
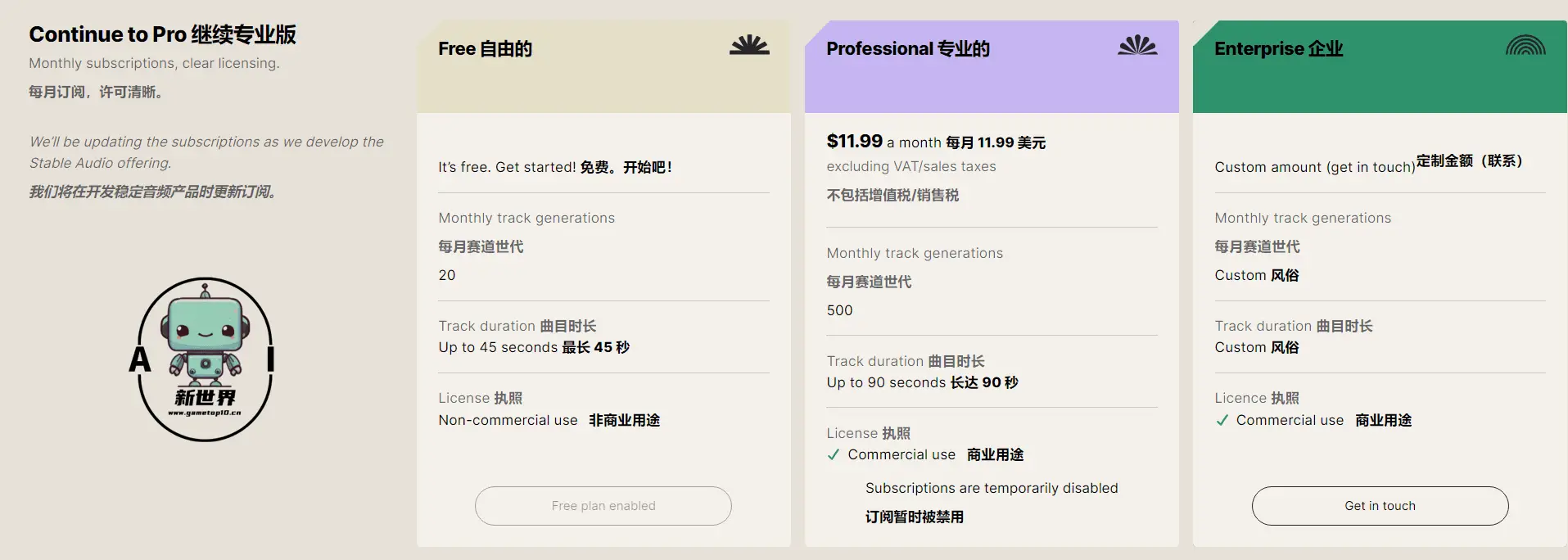
Stable Audio模型利用最新的扩散取样技术,在英伟达A100 GPU上以44.1 kHz的取样速度,不到1秒就能渲染95秒的立体声。Stable Audio目前提供免费与Pro付费版,免费版每月可免费生成20次、最长45秒的声音或音乐,而若每月支付12美元,则可生成500次,最长90秒的音频。官方之后也会将Stable Audio进行开源。(官方说明)
[t-success icon='']如何使用Stable Audio?[/t-success]
1、进入网站后,点击【Try it out】进行注册登录,必须登录才可以使用

2、可以使用邮箱进行注册,也可以使用谷歌账号进行登录
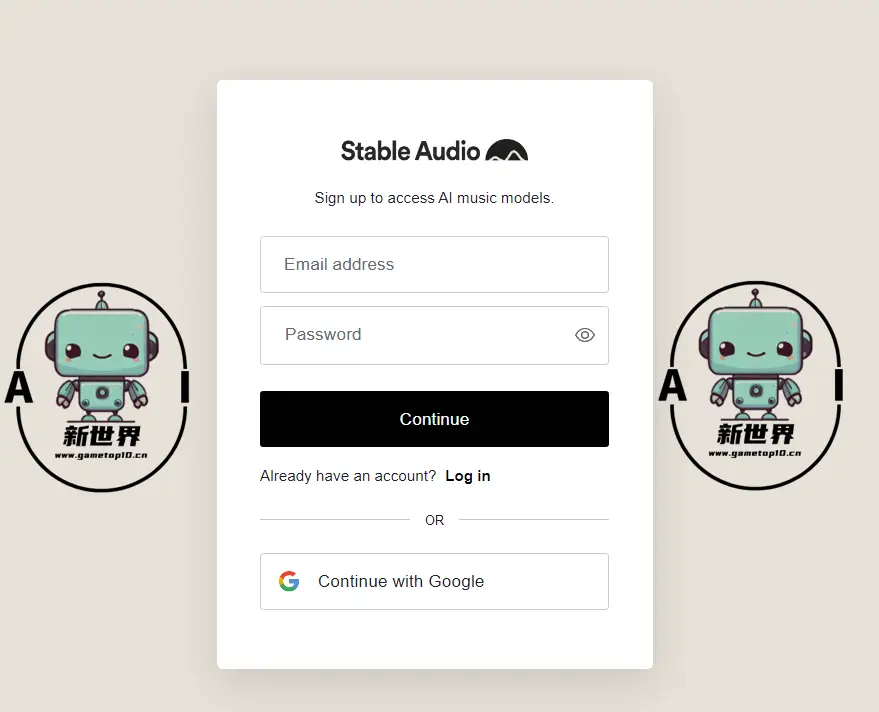
👇勾选官方服务条款,即可进入生成页面

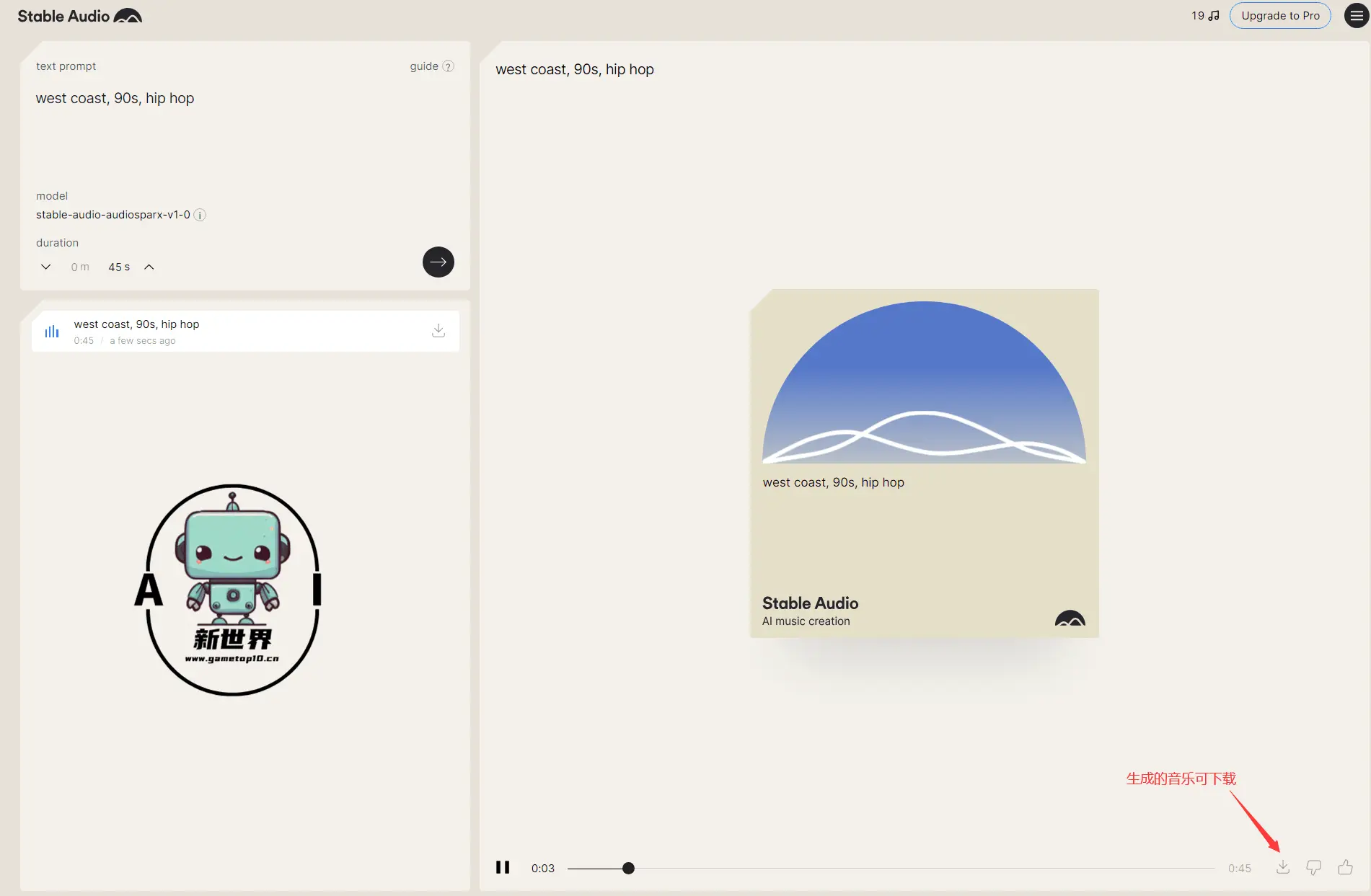
3、官方的生成页面非常简单,输入提示词即可生成音频,目前免费用户最长可以生成45秒钟音频
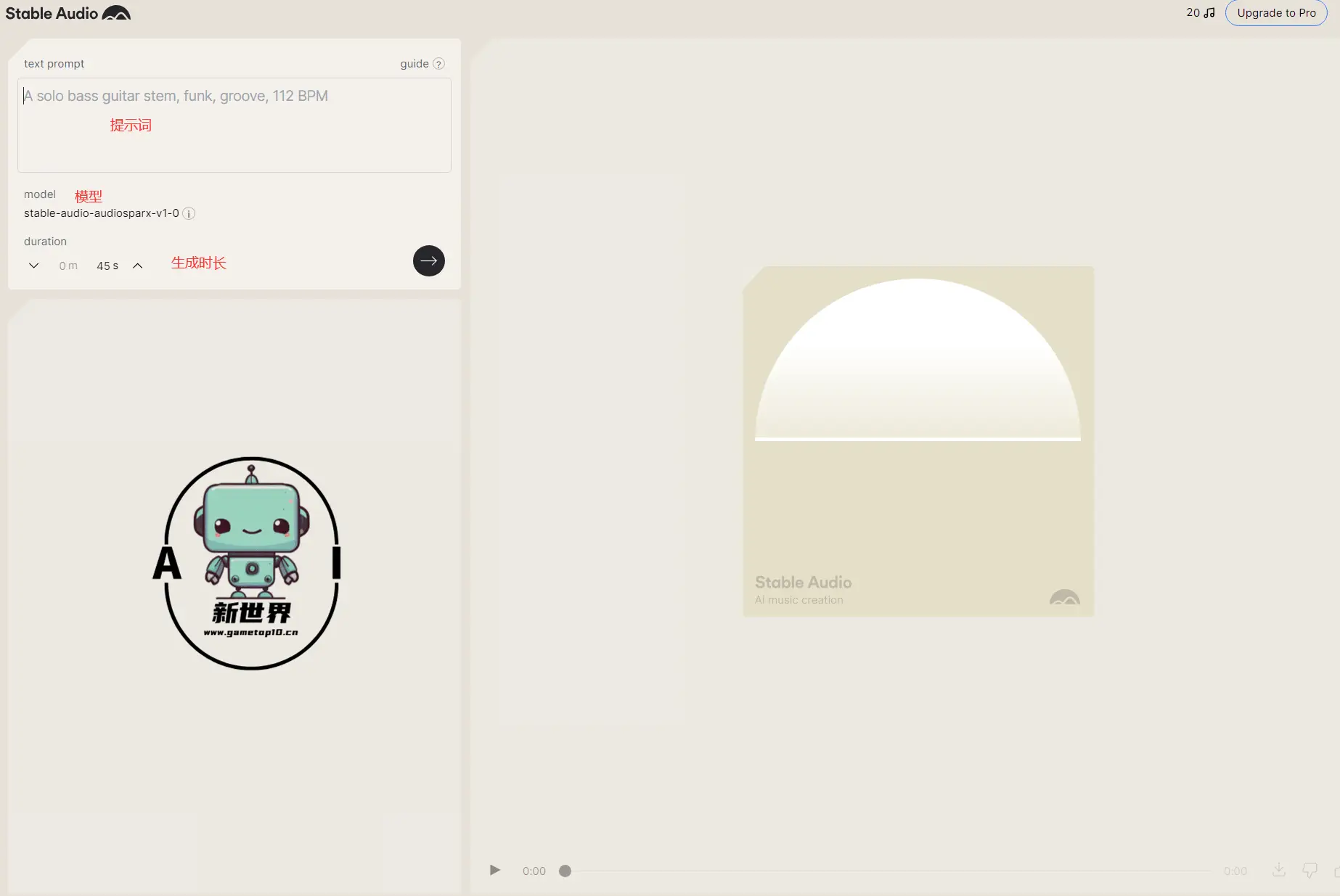
👇比如小编就以“west coast, 90s, hip hop(西海岸,90年代,嘻哈)”为关键词生成了一段45秒的嘻哈音乐
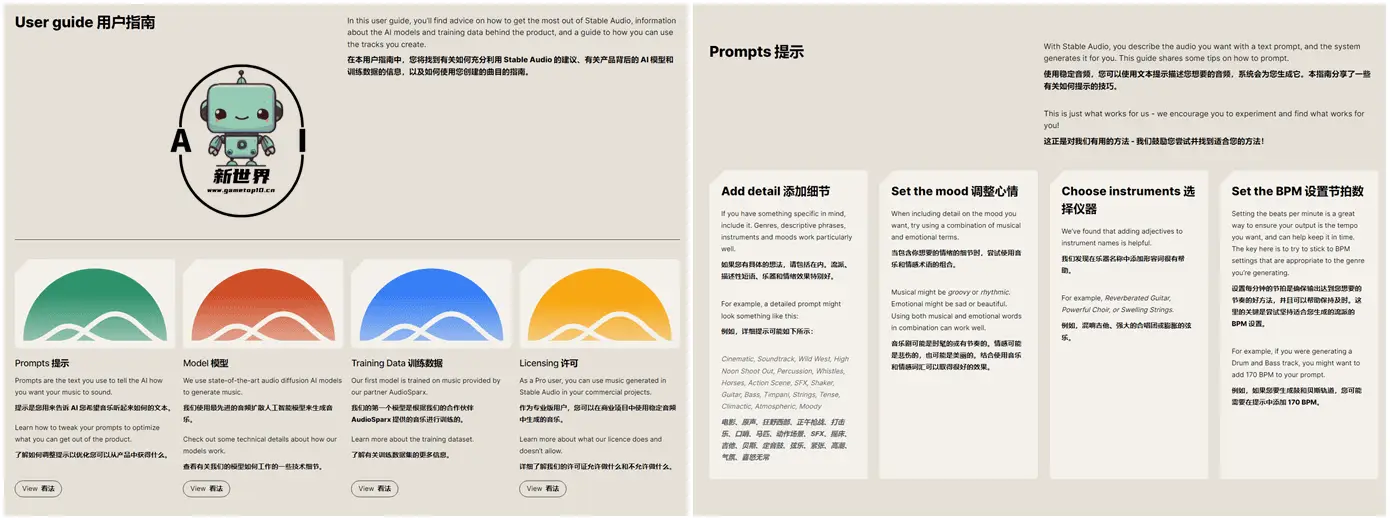
4、官方也非常贴心地为大家准备了用户教程,教大家如何书写提示词
👇针对付费用户与免费用户的区别,官方也给出了说明;对于生成的音频用途官方也有说明

[t-success icon='']结语[/t-success]
该产品刚刚上线,因为流量过大的原因,目前服务不是很稳定,大家还可以等待后续官方开源,那样我们就可以直接在本地电脑进行音频生成。
