
为解决从公开网站上抓取资料的隐私与知识产权争议,OpenAI在北京时间8月8日正式推出一款名为GPTBot的网络爬虫机器人,以更透明方式收集训练AI模型所需的数据信息。根据OpenAI介绍,GPTBot和其他所有网络爬虫一样,从互联网上搜集能够用于训练AI模型的有用数据。但它并不会收集需要付费的、或者违反隐私政策的数据。此外,网站所有者还可以选择限制或者禁止GPTBot爬取网页数据。
若网站管理员不希望被爬虫搜集资料,管理员可以在网站服务器的 robots.txt 文件中完全禁止 GPTBot 抓取信息,或自行决定 GPTBot 抓取网站上的指定信息。
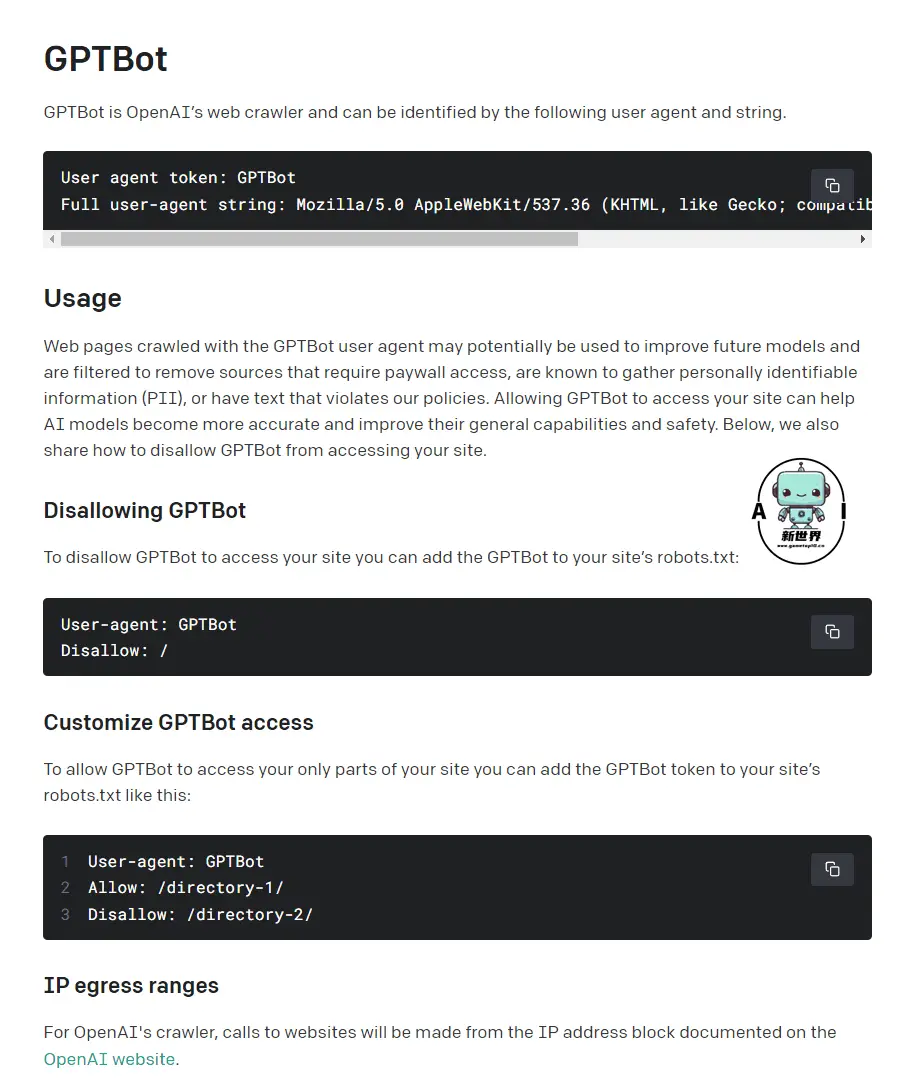
如何禁止GPTBot访问
将GPTBot添加到网站的robots.txt:
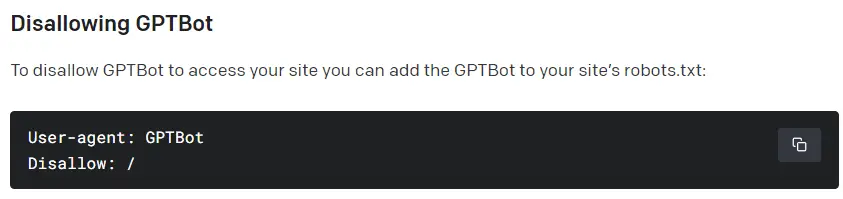
如何限制GPTBot访问,使其只爬取网站的一部分数据
将下列命令添加至网站的robots.txt:
OpenAI还列出了GPTBot使用的IP范围
