文章目录[隐藏]
- [t-success icon='']AI·快讯[/t-success]
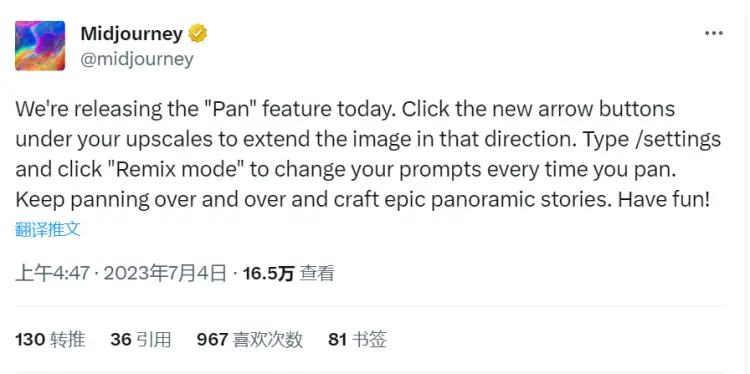
- 1、Midjourney 推出全新功能 pan,按固定方向扩充图片内容
- 2、因可绕过付费机制,OpenAI 暂停测试 Browse with Bing 功能
- 3、北京:促进研发自然语言、多模态、认知等超大规模智能模型
- 4、ChatGPT访问量增速下滑引担忧,专家提醒警惕泡沫化风险
- 5、京东集团CEO许冉:将于7月13日推出大模型
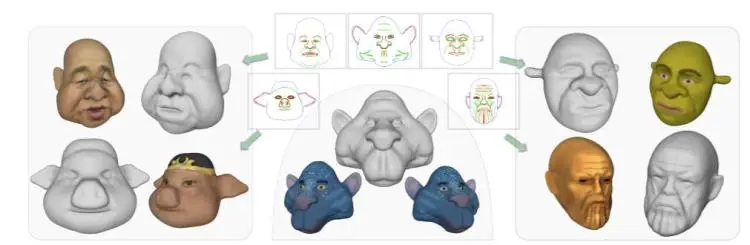
- 6、IEEE公布建模工具 SketchMetaFace,数分钟内建立3D面部模型
- 7、ABB携手微软将生成式AI引入工业应用
- 8、天猫精灵启动内测业内首个大模型终端操作系统
- 9、消息称英伟达正考虑将部分AI GPU订单外包给三星
- 10、配2.2万片英伟达H100 GPU,Inflection AI正开发超级计算机
- 11、研究表明GPT-4模型具备自我纠错能力,有望推动AI代码进一步商业化
- 12、匈牙利公司推出世界首款 AI 研发饮料,口味、包装均由 AI 完成
- 13、中国团队推出脑电图图像生成模型DreamDiffusion,清华、腾讯参与研究
[t-success icon='']AI·快讯[/t-success]
1、Midjourney 推出全新功能 pan,按固定方向扩充图片内容
Midjourney 今天宣布,已推出全新的内容扩展功能 Pan,可以增加生成图片的内容。Pan 功能可以算是 Zoom Out 功能的变种。用户可以在生成一张图片之后,要求Midjourney 沿固定方向扩充图片内容,而不是像 Zoom Out 一样全图按比例缩放。Midjourney 近期一直在不断更新新功能,据悉其最新V6版本或将会在本月内发布。
2、因可绕过付费机制,OpenAI 暂停测试 Browse with Bing 功能
OpenAI 近日暂停了 ChatGPT 的Browse with Bing 功能测试。据悉,该功能测试暂停的原因是因为借助 Browse with Bing 功能,用户可以绕过某些网站的付费机制,让用户免费阅读付费内容。OpenAI 表示,他们正在修复这个问题,但尚未得知官方何时会重新让该功能上架。Browse with Bing 功能是 OpenAI 为 ChatGPT 付费用户提供的一个功能,他允许 ChatGPT 付费用户通过 Bing 搜索引擎来获取信息。
3、北京:促进研发自然语言、多模态、认知等超大规模智能模型
中共北京市委、北京市人民政府印发《关于更好发挥数据要素作用进一步加快发展数字经济的实施意见》的通知。《意见》指出,支持北京经济技术开发区等开展数据基础制度先行先试,打造政策高地、可信空间和数据工场。推进国家数据知识产权试点,探索数据知识产权的制度构建、登记实践、权益保护和交易使用。建立社会数据资产登记中心,建设数据资产评估服务站,先行探索开展数据资产入表。建设数据要素创新研究院,支持数据驱动的科学研究。完善人工智能数据标注库,探索打造数据训练基地,促进研发自然语言、多模态、认知等超大规模智能模型。
4、ChatGPT访问量增速下滑引担忧,专家提醒警惕泡沫化风险
网络分析公司Similarweb统计数据显示,2023年前5个月,ChatGPT全球访问量环比增幅分别为131.6%、62.5%、55.8%、12.6%、2.8%,增长幅度明显下降;6月份ChatGPT的访问量环比下滑9.7%,为其推出以来首次。天使投资人、资深人工智能专家郭涛表示:“当前,中国AGI市场进入‘百家争鸣’时代,但同时已有泡沫化现象出现,例如初创企业估值虚高、上市公司大股东近期频频减持套现等,业界要警惕相关风险。”(来源:证券日报)
5、京东集团CEO许冉:将于7月13日推出大模型
京东集团CEO许冉在今日2023全球数字经济大会主论坛上表示,唯有技术才能创造核心竞争优势,7月13日,京东全球科技探索者大会将发布京东大模型。此前京东云事业部总裁曹鹏曾表示,京东即将推出言犀大规模预训练语言模型。该模型是参数达到千亿级的新一代模型。京东大模型将面向多模态,深入零售、物流、工业等产业场景。据许冉表示,京东将在人工智能、大数据、云计算等领域,不断探索和拓宽科技新边界。
6、IEEE公布建模工具 SketchMetaFace,数分钟内建立3D面部模型
据 Arxiv 页面显示,一个来自 IEEE 的研发团队近日发布论文,公布了一款面向非专业人士的建模工具 SketchMetaFace。SketchMetaFace 可以在几分钟内建立一个拥有高分辨率的 3D 面部模型。研发团队推出了一种名为 IDGMM 的方法,可以快速、高质量地输出3D模型。试验显示,SketchMetaFace在易用性和视觉质量方面相比现有的建模工具有更好的表现。
7、ABB携手微软将生成式AI引入工业应用
据 ABB 中国官微消息,ABB将携手微软将Azure OpenAI服务整合到ABB Ability Genix工业分析和AI套件中。双方将致力于实施生成式AI技术,帮助工业客户解锁运营数据中隐藏的洞见。ABB将通过Azure OpenAI服务,包括GPT-4等大型语言模型(LLM)将生成式AI整合到Genix平台和应用中,实现代码、图像和文本生成等诸多功能。
发布后,新的Genix Copilot应用将提供直观的功能并简化各个流程和运营的关联数据流来增强用户体验。通过为行业管理人员、职能专家和车间工程师提供实时的可执行洞见,改善决策质量并提高生产力。此类洞见有望将资产生命周期延长高达20%,并将意外停机时间减少多达60%。此外,该解决方案还能针对工业温室气体排放和能源利用提供先进监测及优化洞见,帮助客户达成可持续发展和能源转型的目标。
8、天猫精灵启动内测业内首个大模型终端操作系统
从官方APP确认,天猫精灵启动内测业内首个大模型终端操作系统。在天猫精灵APP内测页面上,知识探索、共情互动、生活妙招、灵感启发是四类建议对话场景。用户获得内测资格、同意协议后在线完成固件升级,几十秒之后,天猫精灵的声音、语调和内容生成就都发生显著变化。前期消息看,尚不确定天猫精灵哪些产品都可升级成为AIGC硬件,这是业内第一次通过线上升级,将智能硬件操作系统完全变革为大模型驱动。
9、消息称英伟达正考虑将部分AI GPU订单外包给三星
由于台积电产能供应日益紧张,英伟达正在考虑将部分AI GPU订单外包给三星电子进行制造。行业观察人士指出,如果三星的3nm试验产品通过性能验证并且其2.5D先进封装技术满足英伟达的要求,三星可能会从英伟达获得部分订单。
10、配2.2万片英伟达H100 GPU,Inflection AI正开发超级计算机
人工智能初创公司 Inflection AI 近日宣布正在开发一款超级计算机,配备 2.2 万片英伟达 H100 GPU,可以满足生成式 AI 的发展需求。Inflection AI 由谷歌 DeepMind 联合创始人穆斯塔法・苏莱曼(Mustafa Suleyman)、招聘平台领英联合创始人里德・霍夫曼(Reid Hoffman)创立,专注于开发面向消费者的人工智能产品,被认为是 OpenAI 的主要竞争对手。
11、研究表明GPT-4模型具备自我纠错能力,有望推动AI代码进一步商业化
麻省理工学院(MIT)和微软的研究学者发现,GPT-4 模型具有优秀的代码自我纠错能力,而 GPT-3.5 不具有该特性,目前论文已经发布于 ArXiv 中。研究人员通过研究 GPT-4 表示,当下实际上可以通过“模型的自我纠错”方式,令模型“反思自身所存在的不足之处”,以提升代码片段长度、并改善输出结果的准确度。在经过自我纠错后,GPT-4 模型输出的代码有 71% 达到研究人员设定的要求,而使用 GPT-4 对 GPT-3.5 所生成的代码经过纠错后,这一批代码的通过率也达到了 54%。研究人员表示,当下可以将 GPT-4 的自我纠错方式应用于商业中,在扣除一系列纠错冗余成本后,依然能够产生一定的收益。论文总能够在一定程度上反映行业未来的趋势,因此有望在今后涌现出一批基于 GPT-4 的代码生成器。

12、匈牙利公司推出世界首款 AI 研发饮料,口味、包装均由 AI 完成
匈牙利功能饮料厂商 HELL ENERGY 于 7 月 3 日宣布,该公司成功研发出世界上首款完全由 AI 研制的功能饮料。这种饮料最大的特征,就是从外形设计、配方研发到口味评估、安全措施乃至营销要素,每一个环节都由人工智能完成。具体流程方面,人工智能处理了大量的信息,随后制定了它认为最好的配方。此外,人工智能“不仅考虑了消费者对能量饮料的期望,而且还优先考虑了创造一种卓越和更令人愉快的饮料的目标”。(来源:IT之家)
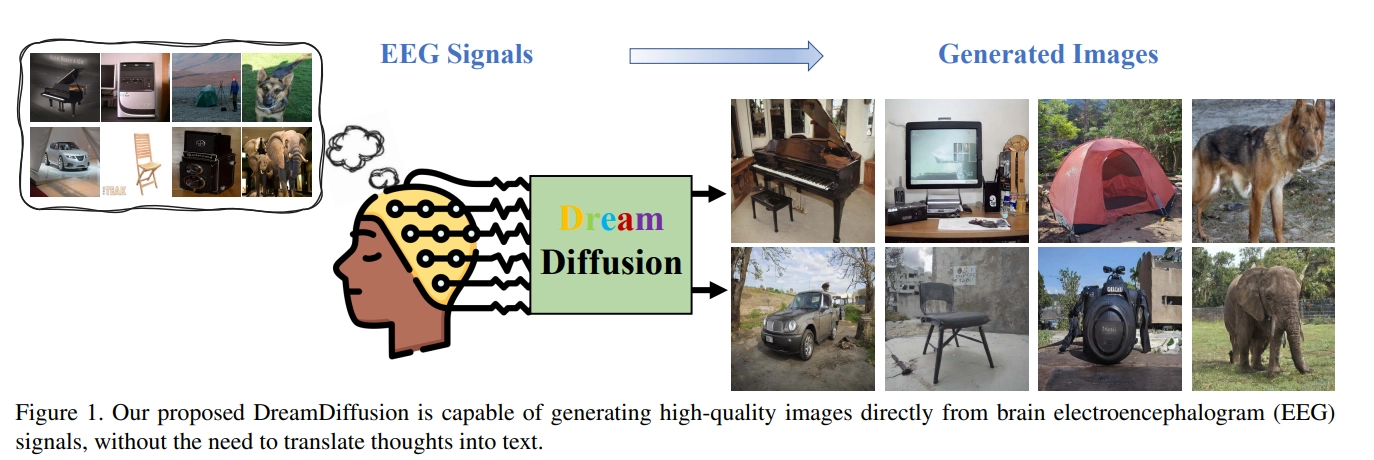
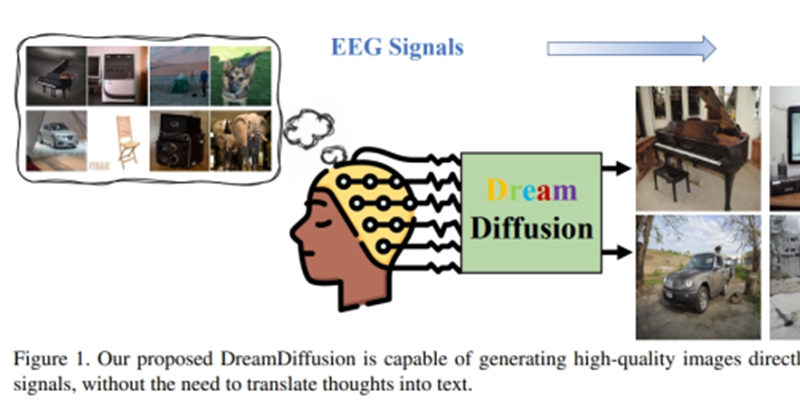
13、中国团队推出脑电图图像生成模型DreamDiffusion,清华、腾讯参与研究
清华大学深圳国际研究生院、腾讯人工智能实验室(AI Lab)和鹏城实验室的研究人员近日发表论文称,研究团队开发了一个名为 DreamDiffusion 的图像生成模型,该模型可以直接通过脑电图(EEG)信号生成高质量图像。相关论文发表于美国康奈尔大学旗下在线学术论文平台 arXiv 上。目前已有不少团队研究了使用文本到图像的扩散模型从人脑生成图像的方法,但大多数采用的都是功能性磁共振成像(fMRI)技术捕捉大脑活动从而生成图像。这种技术缺乏实用性,因为它需要专家操作并且需要昂贵且难以携带的 fMRI 设备。
相比之下,脑电图是一种记录大脑电波活动的非侵入性、低成本方法,且已有一些便携式商业产品可以轻松采集脑电图信号。于是,研究团队提出了一种“稳定扩散”的图像生成方法,能够减少脑电图信号的噪声干预,使扩散模型的预训练更稳定有效。研究团队向 6 位受试者展示了属于 40 个不同对象类别的 2000 张图像,进而通过采集受试者的脑电图信号来生成高质量图像。下图中每组左边标有 GT 的是原始图像,右边的 Sample 图像为脑电图生成图像。