清华大学和OpenCSG的研究人员推出一系列高质量的中文数据集。这些数据集旨在解决中文大语言模型训练中高质量数据稀缺的问题,从而提升中文LLMs的性能。例如,对于一个中文LLM来说,如果没有足够的高质量中文数据,它可能在理解和生成中文内容时表现不佳,而OpenCSG Chinese Corpus通过提供丰富的、高质量的中文数据,帮助LLM更好地学习中文的语义和语法。
主要功能
OpenCSG Chinese Corpus的主要功能是为中文LLMs的预训练、后训练和微调提供高质量的数据支持。具体来说,它包括以下几个方面:
- 预训练:通过提供大规模、高质量的中文文本数据,帮助LLMs学习中文的语言模式和知识结构。
- 后训练:在预训练的基础上,进一步优化模型,使其更好地适应特定的中文任务或领域。
- 微调:针对特定的应用场景或任务,对模型进行微调,以提高其在该任务上的表现。
主要特点
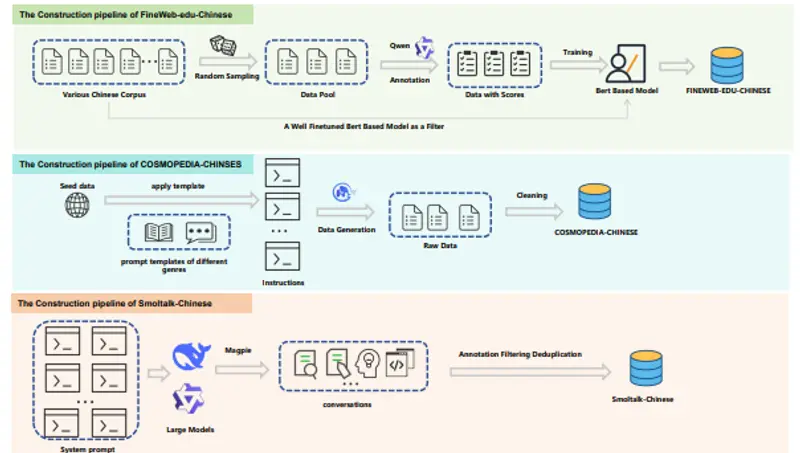
- 高质量文本:所有数据集都经过严格的筛选和过滤,确保文本的质量和教育价值。例如,Fineweb-edu-chinese数据集通过Qwen2-7b-instruct模型对样本进行评分,只保留得分较高的样本。
- 领域覆盖广泛:数据集涵盖了多种领域,包括教育、科技、文学等,能够满足不同任务的需求。
- 可扩展性和可复现性:数据生成和筛选过程是可扩展和可复现的,这意味着可以根据需要生成更多的数据,并且能够保证数据的一致性和质量。
- 开放性:这些数据集是公开可用的,可以在Hugging Face平台上下载,促进了中文NLP社区的发展。
工作原理
OpenCSG Chinese Corpus的工作原理可以分为以下几个步骤:
- 数据收集:从多个开源中文语料库中收集原始数据,如Wudao、Telechat、Map-CC等。
- 数据筛选:使用基于Qwen2的评分模型对数据进行评分,筛选出高质量的样本。例如,Fineweb-edu-chinese数据集通过Qwen2-7b-instruct模型对样本进行0-5分的评分,只保留得分3分以上的样本。
- 数据去重:使用Min-Hash等技术去除重复的样本,确保数据的多样性。
- 数据生成:对于合成数据集如Cosmopedia-chinese,从高质量的种子数据出发,使用大型语言模型生成多种风格的文本,如教科书章节、故事等。
- 数据标注:对于对话数据集如Smoltalk-chinese,使用系统提示和高级中文LLMs生成多轮对话,并进行自动评分和分类,以确保对话的质量和多样性。
具体应用场景
- 教育领域:Fineweb-edu-chinese数据集可以用于训练教育领域的LLMs,帮助生成高质量的教育内容,如教科书章节、教程等。
- 知识问答:Cosmopedia-chinese数据集可以用于训练知识密集型的LLMs,提升模型在知识问答任务中的表现。
- 对话系统:Smoltalk-chinese数据集可以用于训练对话系统,使其能够处理复杂的对话任务,如多轮对话、任务导向的对话等。
- 文本生成:这些数据集可以用于训练文本生成模型,生成各种风格和领域的高质量文本,如新闻报道、故事、教程等。
通过这些高质量的数据集,OpenCSG Chinese Corpus为中文LLMs的发展提供了坚实的基础,促进了中文自然语言处理技术的进步。