谷歌的研究团队近期推出了一种名为Titans的新机器学习架构,该架构旨在通过引入注意力机制和元上下文记忆来提升大语言模型(LLMs)的能力。基于Transformer架构的LLMs因其出色的上下文学习能力和扩展性而引领了序列建模的革命,但随着输入长度的增长,其计算需求呈二次方增加的问题也日益凸显。为了解决这一挑战,Titans架构应运而生。
解决方案概述
Titans创新地提出了一个双记忆系统,其中注意力作为短期记忆用于精确的局部依赖建模,而一个新的神经记忆组件则充当长期存储以保留持久信息。这种设计不仅克服了传统Transformer在处理长序列时遇到的计算瓶颈,还显著提升了模型在实际应用中的适用性和效率。
架构特点与优势
- 三部分设计:Titans由核心模块、长期记忆分支和持久记忆组件构成。核心模块负责使用有限窗口大小的注意力进行短期记忆和数据处理;长期记忆分支实现了用于存储历史信息的神经记忆模块;持久记忆组件包含可学习且独立于具体数据的参数。
- 优化技术:为了增强性能,Titans采用了多种优化策略,包括残差连接、SiLU激活函数以及查询和键的ℓ2范数归一化等。此外,一维深度可分离卷积层的应用进一步提升了模型的表现力。
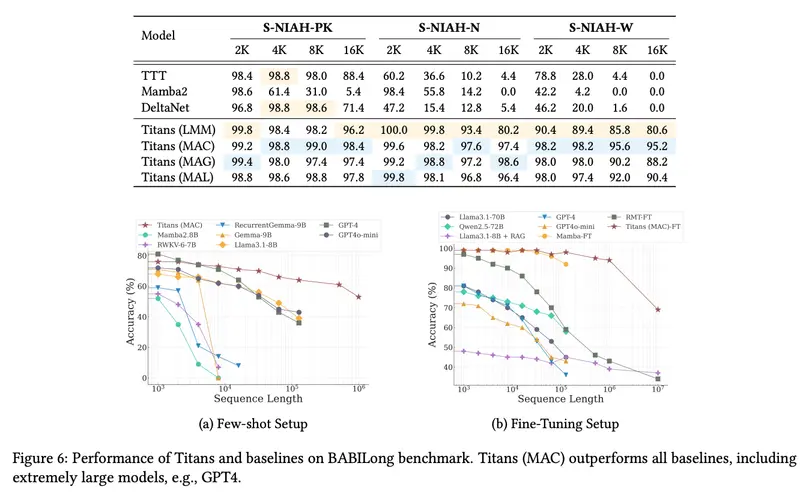
- 实验验证:实验结果表明,Titans架构下的三种变体——MAC、MAG和MAL,在多种任务中均展现了超越现有混合模型的性能,特别是在处理长序列时表现尤为突出。例如,在“大海捞针”任务中,Titans成功处理了从2K到16K标记范围内的序列,并优于多个基线模型。
结论
Titans代表了序列建模领域的一个重大进步,它不仅解决了Transformer在处理长序列时面临的计算难题,还通过引入高效的长期记忆机制提高了模型的记忆能力和灵活性。能够有效处理超过200万个标记的序列,同时保持高精度,这为未来开发更加复杂和强大的AI应用奠定了基础。对于研究人员和开发者来说,Titans提供了一个全新的视角来探索如何更有效地管理和利用大规模数据集中的信息。