在自然语言处理(NLP)领域,随着多语言应用和跨语言任务需求的增长,强大的嵌入模型变得尤为重要。这些模型是检索增强生成(RAG)系统和其他AI解决方案的基础。然而,现有模型往往面临数据噪声大、领域覆盖有限及多语言数据集管理效率低下等问题。为解决这些问题,哈尔滨工业大学(深圳)的研究团队推出了KaLM-Embedding,这是一个强调数据质量和创新训练方法的多语言嵌入模型,并以MIT许可证开源发布。
- GitHub:https://github.com/HITsz-TMG/KaLM-Embedding
- 模型:https://huggingface.co/collections/HIT-TMG/kalm-embedding-67316afa4c56f4fc1f58764b
数据驱动的设计
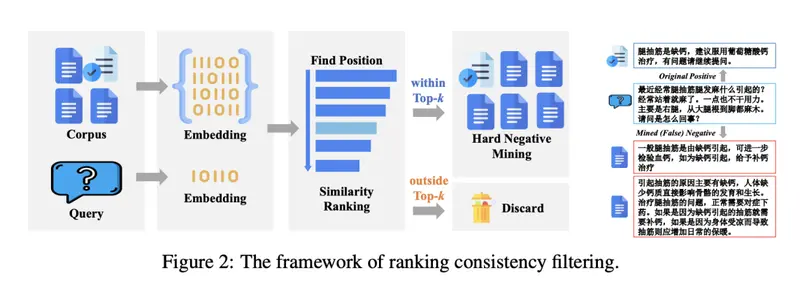
KaLM-Embedding基于Qwen 2-0.5B构建,是一款设计紧凑且高效的多语言嵌入模型,特别适合资源受限的实际应用场景。该模型的核心优势在于其数据驱动的设计,包含55万条合成数据样本,通过角色技术生成,确保了数据的多样性和相关性。此外,采用了排序一致性过滤技术来去除噪声数据和假阴性样本,从而提高训练数据的质量和鲁棒性。
技术特性与优势
KaLM-Embedding结合了多种先进技术,提供强大的多语言文本嵌入能力。其中,Matryoshka表示学习支持灵活调整嵌入维度(从64到896维),允许根据不同的应用场景进行优化。训练过程分为两个阶段:弱监督预训练和监督微调,使用超过70个涵盖多种语言和领域的多样化数据集。采用的半同质任务批处理策略进一步优化了训练效果。
基于Qwen 2-0.5B架构,KaLM-Embedding相较于传统的BERT类模型,在嵌入任务中展现了更强的适应性。
性能与基准测试结果
在大规模文本嵌入基准测试(MTEB)中,KaLM-Embedding取得了平均64.53分的成绩,树立了参数量少于10亿模型的新标杆。尤其在中文和英文MTEB上分别获得了64.13和64.94的高分,显示了其出色的多语言处理能力。即使对于那些微调数据有限的语言,模型也展示了强大的泛化能力。
消融研究揭示了Matryoshka表示学习和排序一致性过滤对性能提升的重要性,同时指出了未来改进的方向,如优化低维嵌入以进一步提高效果。