香港大学和Salesforce 研究的研究人员推出一个统一的纯视觉基础框架AGUVIS,用于构建能够在不同平台上自动执行图形用户界面(GUI)任务的智能代理。AGUVIS通过利用基于图像的观察和自然语言指令与视觉元素的关联,以及一致的动作空间,来实现跨平台的泛化能力。这个系统能够理解高分辨率和复杂的用户界面,并将自然语言指令映射到视觉观察上,从而规划和推理出完成任务的有效步骤。
例如,你想要在一个电子商务网站上购买一款产品。AGUVIS能够理解网站的视觉布局,并根据用户输入的指令(如“选择红色款式”或“添加到购物车”)来识别和操作界面元素。它不需要依赖于网站的特定文本或代码结构,而是直接通过视觉识别来执行任务。
主要功能
- 理解GUI:理解高分辨率和复杂用户界面,把握上下文以便进行后续推理。
- GUI定位(Grounding):将自然语言指令映射到用户界面的视觉观察上。
- 规划与推理:结合当前和以往的多模态观察结果以及动作历史,生成连贯有效的下一步操作。
主要特点
- 跨平台一致性:AGUVIS能够在网站、桌面和移动设备等多种平台上操作,具有很好的泛化能力。
- 纯视觉框架:通过图像观察而非文本表示,更符合人类的认知过程,并减少了推理时的计算量。
- 显式规划与推理:模型内部集成了规划和推理能力,提高了自主导航和交互的能力。
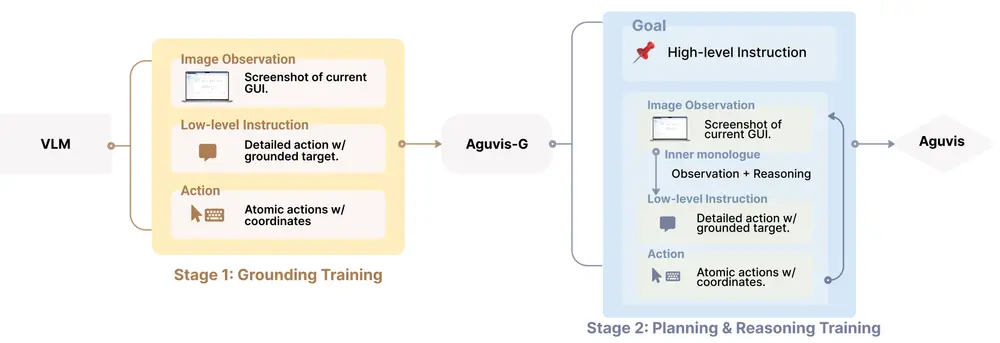
工作原理
AGUVIS的工作原理基于两个主要阶段:
- 定位训练(Grounding Training):在这个阶段,模型学习理解和交互单个GUI截图中的对象。
- 规划与推理训练(Planning & Reasoning Training):在有了定位基础之后,模型进一步学习如何执行多步骤任务,通过详细的内部独白(inner monologue)数据,模型能够适应不同的认知复杂性。
具体应用场景
- 网站任务自动化:如在线购物、填写表单、搜索信息等。
- 桌面应用自动化:比如文件管理、应用程序操作等。
- 移动设备任务:在智能手机上执行如应用切换、数据输入等任务。
AGUVIS通过其先进的视觉语言模型和大规模的、多步骤的、跨平台的数据集,展示了在各种场景下执行任务的能力,无需依赖外部闭源模型,为自动化GUI任务提供了一个强大的工具。