艾伦人工智能研究所(AI2)宣布发布Tülu 3,这是一系列最先进的指令遵循模型,旨在为AI能力设定新的基准。此次发布包括最先进的功能、方法和工具,为研究人员和开发者提供了一个全面的、开源的解决方案。通过Tülu 3,AI2成功解决了从对话AI到数学、推理和评估等复杂问题解决领域的广泛任务。
- 项目主页:https://allenai.org/tulu
- 模型:https://huggingface.co/collections/allenai/tulu-3-models-673b8e0dc3512e30e7dc54f5
关键特点
模型家族
Tülu 3是一个优先考虑透明性、开放性和最先进性能的模型家族。这些模型基于Meta的Llama 3.1框架,并在一个包含公开可用、合成和人类创建数据的广泛数据集上进行了微调。这种方法确保了Tülu 3在包括数学、GSM8K和IFEval等专业领域以及通用聊天和推理任务在内的多样化任务中表现出色。
模型尺寸
Tülu 3家族包括两个主要模型尺寸:
- Tülu 3 8B(Llama-3.1-Tulu-3-8B)
- Tülu 3 70B(Llama-3.1-Tulu-3-70B)
训练技术
这些模型使用了先进的训练技术,包括:
- 顺序微调(SFT):逐步优化模型以适应特定任务。
- 直接偏好优化(DPO):通过直接优化模型以匹配人类偏好来提高性能。
- 价值正则化强化学习(RLVR):结合强化学习和价值正则化,以提高响应质量和稳定性。
性能指标
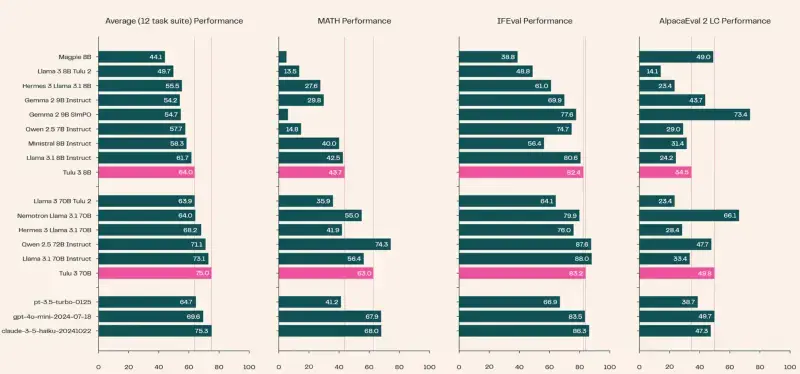
Tülu 3模型在多个基准评估中展示了显著的性能:
- MMLU(0-shot思维链):在多任务多语言理解任务中表现出色。
- GSM8K(8-shot思维链):8B模型得分87.6,70B模型得分93.5。
- HumanEval:70B模型达到92.4%的pass@10率。
- 安全任务:8B和70B模型分别得分85.5和88.3,展示了处理敏感和复杂查询的可靠性。
开放性和可访问性
Tülu 3真正与众不同之处在于其对开放性的承诺。AI2已经将模型、训练数据集、评估代码和方法完全开源。研究人员和开发者可以访问以下资源:
- 训练仓库:包含训练代码和数据集。
- 评估仓库:包含评估代码和基准测试结果。
- 技术报告:详细介绍了模型的架构和能力。
- Playground平台:提供了一个互动演示,让用户亲自探索模型的性能和应用。
先进的训练技术
Tülu 3模型的训练结合了先进的后训练技术,以最大化性能:
- RLVR方法:引入了强化学习概念,以提高响应质量同时保持价值正则化。
- 关键超参数:学习率为3*10^(-7),gamma为1.0,KL惩罚系数范围为[0.1, 0.05, 0.03, 0.01]。
- 支持的最大token长度:标准支持2048个token,数学任务扩展至4096个token。
创新的聊天模板
Tülu 3采用了创新的聊天模板,以简化对话AI交互:
- 用户和助手角色:模板嵌入了用户和助手角色,确保无缝和连贯的交流。
- 默认系统提示:指导模型在聊天会话中的行为,例如“您是Tülu 3,一个由艾伦人工智能研究所构建的有帮助且无害的AI助手”。
超越聊天的应用
尽管Tülu 3在对话任务中表现出色,但其能力不仅限于简单的对话。模型在复杂的推理基准测试中也表现出色:
- 数学任务:70B模型得分63.0。
- BigBenchHard任务:70B模型得分82.0。
- 内容生成、总结和编码:在HumanEval和HumanEval+任务中,70B模型分别达到了92.4和88.0的pass@10分数。
局限性和挑战
尽管Tülu 3具有显著的能力,但它并非没有局限性:
- 安全训练:模型在安全训练方面有限,并且不具备一些专有模型中的循环过滤机制。
- 训练数据集:确切组成仍未公开,引发了对其潜在偏见的担忧。