文章目录[隐藏]
大语言模型(LLMs)已成为许多AI系统的核心,显著推动了自然语言处理(NLP)、计算机视觉甚至科学研究的进步。然而,这些模型也带来了自身的挑战。随着对更好AI能力的需求增加,对更复杂和更大模型的需求也随之增加。LLMs的规模和计算需求使得训练和推理成本高昂,促使研究人员探索更高效的架构。一种受欢迎的解决方案是专家混合(MoE)模型,通过选择性激活专业组件来提高性能。尽管有潜力,但很少有大规模的MoE模型被开源供社区使用,限制了创新和实际应用。
Hunyuan-Large:腾讯的重要贡献
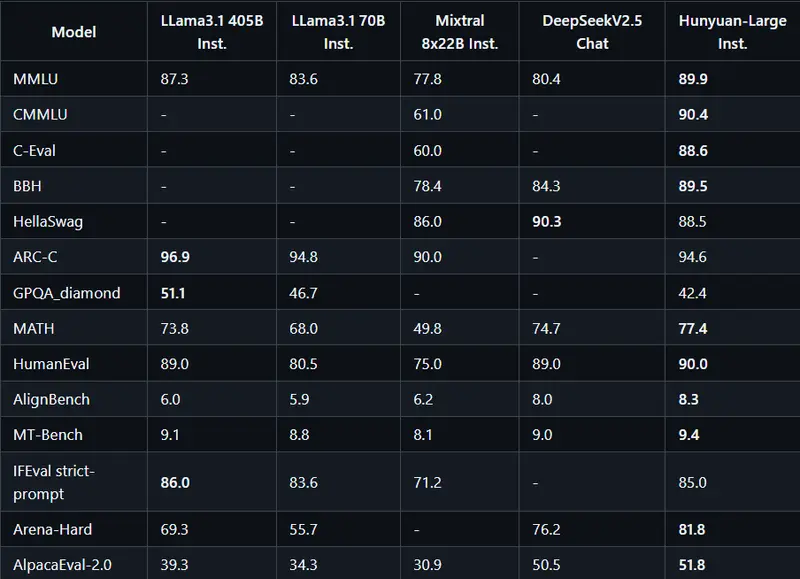
腾讯通过发布Hunyuan-Large迈出了重要一步,这是目前行业中最大的基于Transformer的MoE开源模型。Hunyuan-Large总共有3890亿参数,其中520亿是活跃的,设计用于处理长达256K个token的极大上下文。该模型结合了前所未有的尖端技术来应对NLP和通用AI任务,在某些情况下,其性能超越了其他领先模型,如LLama3.1-70B和LLama3.1-405B。
- 项目主页:https://llm.hunyuan.tencent.com
- GitHub:https://github.com/Tencent/Tencent-Hunyuan-Large
- 模型:https://huggingface.co/tencent/Tencent-Hunyuan-Large
- API地址:https://cloud.tencent.com/product/hunyuan
- Demo:https://huggingface.co/spaces/tencent/Hunyuan-Large
腾讯在 Hugging Face 开源了 Hunyuan-A52B-Pretrain 、 Hunyuan-A52B-Instruct 和 Hunyuan-A52B-Instruct-FP8,并发布了技术报告和训练推理操作手册,详细介绍了模型能力和训练与推理的操作。
技术进步与创新
Hunyuan-Large通过多种技术进步实现了其令人印象深刻的性能:
- 大规模预训练:
- 数据量:该模型在七万亿个token上进行了预训练,其中包括1.5万亿个合成数据token。
- 数据多样性:这些数据涵盖了数学、编码和多语言等多样化领域,使模型能够有效泛化,超越其他同等规模的模型。
- 混合专家路由策略:
- 选择性激活:通过选择性激活专业组件,提高了模型的效率和性能。
- 专家特定学习率:允许不同模型组件更优化地训练,平衡共享专家和专业专家之间的负载。
- KV缓存压缩:
- 内存优化:减少了推理期间的内存开销,使得在保持高质量响应的同时高效扩展模型成为可能。

性能与应用
Hunyuan-Large的发布具有重要意义。它不仅提供了与真正大规模MoE模型合作的机会,还附带了开源代码库和预训练检查点,便于进一步研究和开发。基准测试显示,Hunyuan-Large在关键NLP任务(如问答、逻辑推理、编码和阅读理解)上优于现有模型。例如,它在MMLU基准测试中以88.4分超越了LLama3.1-405B模型的85.2分。这一成就突显了Hunyuan-Large训练和架构的效率,尽管其活跃参数较少。
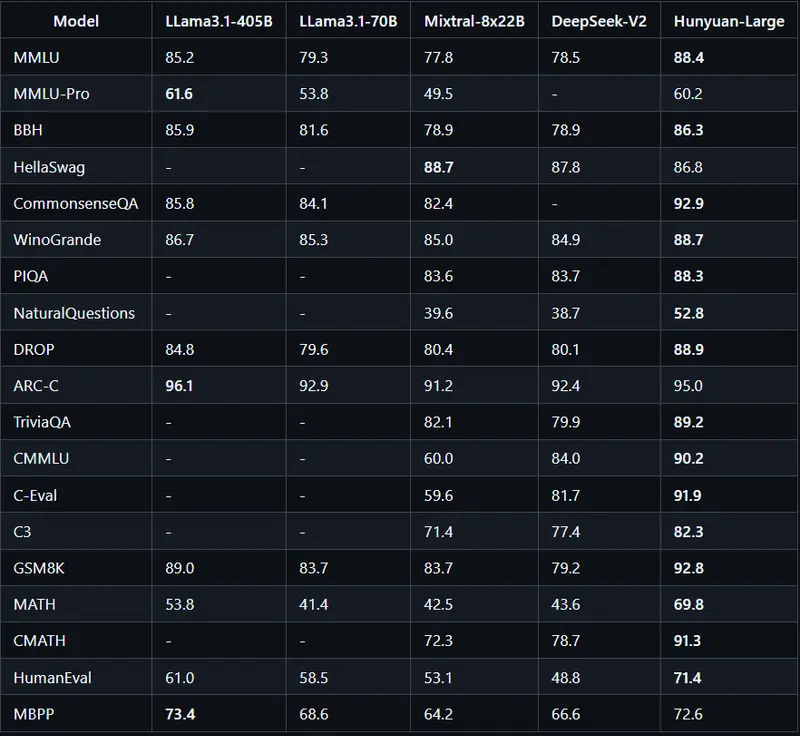
通过在需要长上下文理解的任务中表现出色,Hunyuan-Large还解决了当前LLM能力中的一个关键差距,使其特别适用于需要处理扩展文本序列的应用。