文章目录[隐藏]
在快速发展的世界中,AI和机器学习的成功不仅取决于模型的训练效果,还取决于模型在实际应用中的部署和运行效率。对于数据科学家和机器学习工程师而言,加载训练好的模型进行推理的缓慢和繁琐过程一直是令人头疼的问题。无论模型是存储在本地还是云端,加载过程中的低效都会成为瓶颈,降低生产力并延迟宝贵洞察的交付。
在现实场景中,这一问题尤为重要,因为推理必须既快速又可靠,以满足用户期望。为此,Run AI最近推出了一款开源解决方案——Run AI: Model Streamer,旨在大幅减少加载推理模型所需的时间。
Run AI: Model Streamer的关键特点
- 显著提高加载速度:
- 六倍加速:Run AI: Model Streamer能够将模型加载速度提高到六倍,显著缩短了从存储到内存的时间。
- 基准测试结果:从Amazon S3加载模型的时间从37.36秒减少到4.88秒;从SSD加载模型的时间从47秒减少到7.53秒。
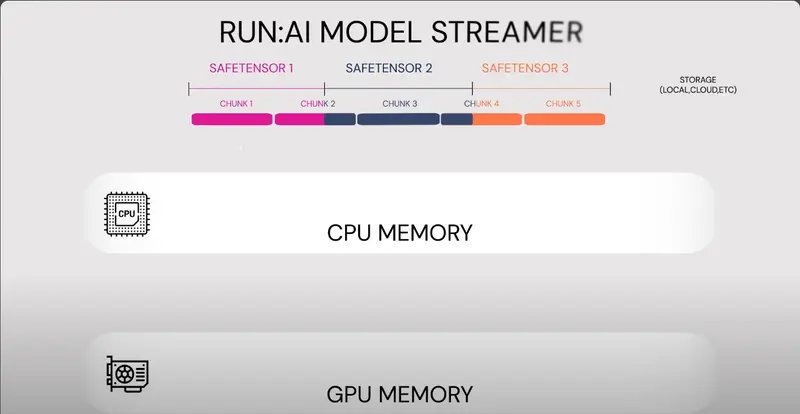
- 广泛的存储兼容性:
- 支持多种存储类型:Run AI: Model Streamer支持所有主要的存储类型,包括本地存储、基于云的解决方案(如Amazon S3)、网络文件系统(NFS)等。
- 无缝集成:开发者无需担心兼容性问题,无论他们的模型存储在哪里。
- 原生集成流行的推理引擎:
- 无需格式转换:Run AI: Model Streamer与流行的推理引擎原生集成,消除了耗时的模型格式转换需求。
- 直接加载模型:例如,来自Hugging Face的模型可以直接加载,无需任何转换,显著减少了部署过程中的摩擦。
- 开源项目:
- 推动创新:通过将Run AI: Model Streamer作为开源项目发布,Run AI赋予开发者创新并利用该工具在各种应用中的能力。
- 社区支持:开源项目鼓励社区贡献和改进,进一步提升了工具的稳定性和功能性。
实际应用案例
- 实时推荐引擎:
- 快速响应:在电商和社交媒体平台中,实时推荐引擎需要在毫秒级内提供个性化推荐。Run AI: Model Streamer通过显著缩短模型加载时间,确保了推荐引擎的快速响应。
- 关键医疗诊断:
- 高效诊断:在医疗领域,快速准确的诊断至关重要。Run AI: Model Streamer通过加速模型加载,提高了诊断系统的效率和可靠性。
- 自动驾驶系统:
- 实时决策:自动驾驶汽车需要在短时间内处理大量传感器数据并作出决策。Run AI: Model Streamer通过优化模型加载,确保了系统的实时性和安全性。
Run AI: Model Streamer通过提供高速、优化的模型加载方法,解决了AI工作流中的一个关键瓶颈。凭借高达六倍的加载速度和跨不同存储类型的无缝集成,该工具有望使模型部署更加高效。能够直接加载模型而无需任何格式转换进一步简化了部署管道,使数据科学家和工程师能够专注于他们最擅长的——解决问题和创造价值。
通过开源这一工具,Run AI不仅在社区内推动了创新,还为模型加载和推理设定了新的基准。随着AI应用的不断增加,像Run AI: Model Streamer这样的工具将在确保这些创新快速高效地发挥其全部潜力方面发挥至关重要的作用。