加州大学伯克利分校、英伟达、麻省理工学院和清华大学的研究人员共同提出了一种名为COAT的新型FP8训练框架。COAT旨在显著减少大模型训练中的内存占用,同时保持高性能。这一框架通过两项关键创新解决了现有方法的局限性,从而在多种任务中实现了显著的改进。
例如,我们正在训练一个具有数十亿参数的大语言模型(LLM),如自然语言处理领域的GPT或BERT模型。在传统的训练方法中,这些模型需要大量的内存来存储优化器状态(如梯度和动量)和中间激活值。COAT框架通过将这些数据压缩到FP8格式,显著减少了内存占用,使得在有限的硬件资源下训练更大的模型成为可能。
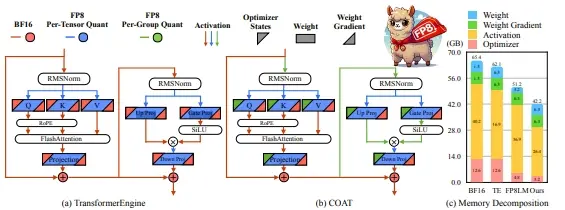
现有框架的局限性
现有的FP8训练框架主要通过将FP8计算应用于线性层来加速训练,但优化器状态和激活仍然保持在较高的精度(如FP32或BF16)。这种做法未能充分利用内存使用,限制了训练效率的提升。
COAT的关键创新
- 动态范围扩展:
- 目的:使优化器状态分布更接近FP8表示范围,从而减少量化误差。
- 方法:通过动态调整优化器状态的范围,使其更适合FP8表示。这一技术有效地减少了量化过程中的信息损失,提高了模型的训练精度。
- 混合粒度激活量化:
- 目的:优化激活内存的使用,减少内存占用。
- 方法:结合张量级和组级量化策略,灵活地选择最适合当前任务的量化粒度。这种混合策略不仅减少了内存占用,还保持了激活的精度。
实验结果
实验表明,COAT在多个方面表现优异:
- 内存占用:相比BF16,COAT有效地减少了1.54倍的端到端训练内存占用。
- 性能:在各种任务中,如大型语言模型的预训练和微调、视觉语言模型的训练,COAT实现了几乎无损的性能。
- 训练加速:COAT实现了相比BF16的1.43倍端到端训练加速,表现与TransformerEngine的加速相当或超越。
应用前景
COAT的推出为大规模模型训练提供了几个重要的优势:
- 高效的全参数训练:COAT使得在更少的GPU上进行高效的全参数训练成为可能,降低了硬件成本。
- 批量大小翻倍:在分布式训练设置中,COAT能够将批量大小翻倍,进一步提高训练效率。
- 扩展性:COAT为扩展大规模模型训练提供了一个实用的解决方案,适用于多种深度学习任务和应用场景。
总结
COAT通过动态范围扩展和混合粒度激活量化两项关键技术,显著提高了FP8训练的效率和性能。这一框架不仅减少了内存占用,还保持了高性能,为大规模模型训练提供了一个实用且高效的解决方案。未来,随着这一技术的进一步发展和应用,我们有理由期待更多创新的深度学习模型和应用。