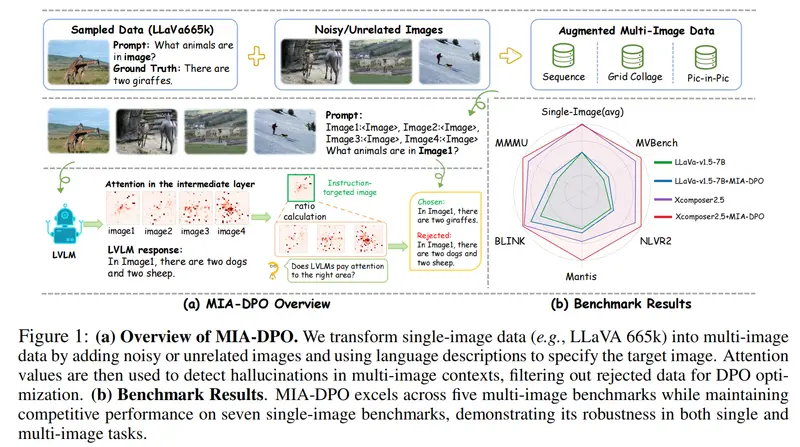
视觉偏好对齐涉及训练大型视觉-语言模型(LVLMs)以预测人类对视觉输入的偏好。现有的方法主要设计用于单图像场景,但由于多样化的多图像训练数据稀缺以及标注选中/拒绝对的高成本,这些方法在处理多图像任务时面临挑战。为此,上海交通大学、上海市人工智能实验室、香港中文大学和 MThreads的 研究人员推出提出了多图像增强的直接偏好优化(MIA-DPO),这是一种能有效处理多图像输入的视觉偏好对齐方法。
它旨在提升大型视觉语言模型(LVLMs)在处理多图像任务时的表现。在现实世界中,我们经常需要理解和比较多个图像,比如在网页上浏览商品图片或者在报告中分析多个图表。MIA-DPO通过优化这些模型,使它们能够更准确地处理和理解多图像输入,减少“幻觉”(hallucinations)现象,即模型错误地识别或生成不存在于图像中的信息。
例如,你正在网上购物,网页上展示了多个不同角度的商品图片。使用MIA-DPO优化过的LVLM能够更准确地回答关于这些图片的问题,比如“商品的颜色是什么?”或者“哪个图片显示了商品的背面?”。如果没有MIA-DPO,LVLM可能会混淆不同图片中的信息,导致错误的回答。
主要功能和特点
- 多图像处理能力提升:MIA-DPO通过扩展单图像数据,使其能够在多图像环境中更有效地工作。
- 成本效益:它减少了构建多图像数据集的成本,通过将不相关的图像以网格拼贴或画中画格式组合,显著降低了多图像数据注释的成本。
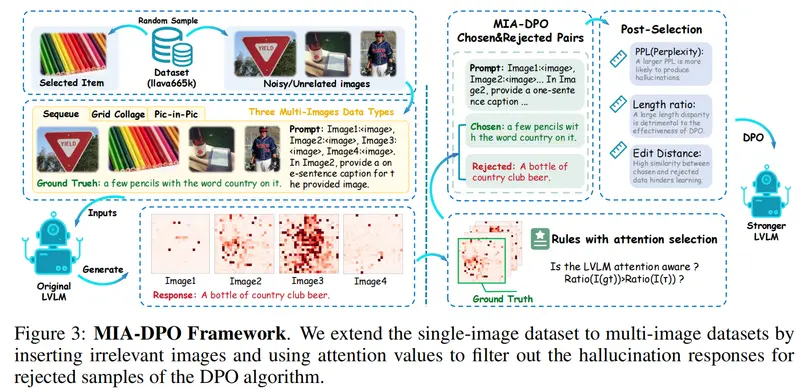
- 注意力机制:利用LVLMs的注意力值来识别和过滤模型可能错误关注的拒绝响应,从而构建选择/拒绝对,无需人工注释、额外数据或外部模型/API。
- 架构兼容性:MIA-DPO与不同的LVLM架构兼容,并且在多个多图像基准测试中表现优于现有方法。
工作原理
- 数据扩展:将单图像数据通过添加噪声或无关图像扩展到多图像上下文。
- 注意力感知选择:利用注意力值来识别模型可能错误关注的图像,过滤出拒绝样本用于DPO优化。
- DPO算法应用:将构建的多图像提示和选择/拒绝对应用于DPO算法,从而优化模型。

实验结果
MIA-DPO 方法在多个基准测试中表现出色,具体如下:
- 五个多图像基准测试:MIA-DPO 在这些基准测试中均优于现有方法。
- LLaVA-v1.5:平均性能提升为3.0%。
- InternLM-XC2.5:平均性能提升为4.3%。
其他优点
- 兼容性:MIA-DPO 与各种架构兼容,可以应用于不同的LVLMs。
- 单图像任务影响:MIA-DPO 对模型理解单图像的能力影响最小,确保了模型在单图像任务中的表现不受损害。
具体应用场景
- 电子商务:在商品页面上,帮助用户理解多个商品图片,提供更准确的视觉信息。
- 教育和研究:在学术报告或研究论文中,分析和比较多个图表和图像数据。
- 新闻和媒体:在新闻报道中,对多个图像证据进行验证和分析,提高报道的准确性。
- 安全和监控:在安全监控领域,对多个摄像头捕获的图像进行分析,以识别异常行为或事件。
MIA-DPO通过提高LVLMs在多图像任务中的表现,为需要处理和理解多个视觉输入的现实世界应用提供了强大的技术支持。