
OpenAI的研究人员发布论文,论文的主题是关于简化、稳定和扩展连续时间一致性模型(Consistency Models, CMs),这些模型是一类基于扩散的生成模型,特别优化于快速采样。这些模型在图像生成、3D建模、音频合成和视频生成等领域取得了革命性的进展。论文的核心目标是解决现有连续时间CMs训练中的不稳定性问题,并提出了一系列改进措施,使得这些模型能够以前所未有的规模进行训练,达到1.5B参数量级。
例如,在图像生成任务中,我们可能需要生成一张具有特定风格的图像。传统的扩散模型可能需要数十甚至数百步才能生成一个样本,而本文提出的连续时间CMs能够在较少的步骤内生成高质量的图像,比如仅用两步就能达到与最佳扩散模型相近的样本质量。
主要功能和特点
- 简化理论框架:提出了一个简化的理论框架,统一了之前扩散模型和CMs的参数化,识别了训练不稳定的根源。
- 改进的参数化:引入了TrigFlow,一种新的扩散模型表述,简化了模型的参数化和概率流ODE。
- 网络架构优化:改进了网络架构,包括时间条件和自适应分组归一化。
- 训练目标重构:重新构建了连续时间CMs的训练目标,引入自适应权重和关键项的归一化,以及渐进式退火策略以实现稳定和可扩展的训练。
- 高性能:在CIFAR-10、ImageNet 64×64和ImageNet 512×512等数据集上,使用仅两步采样步骤的算法,实现了与最佳现有扩散模型相近的FID得分。
工作原理
- TrigFlow参数化:通过TrigFlow框架,将扩散过程、模型参数化、训练目标和采样器统一起来,简化了模型的表述和训练过程。
- 连续时间CMs训练:通过改进的参数化和网络架构,以及新的训练目标,使得连续时间CMs能够避免离散时间CMs中的数值积分误差,提供更准确的训练信号。
- 自适应权重和归一化:通过自适应权重和归一化技术,平衡不同时间步的损失方差,提高模型训练的稳定性和效率。
以下是官方对此的介绍:
简化、稳定和扩展连续时间一致性模型
连续时间一致性模型只需两个采样步骤即可达到与领先扩散模型相当的样本质量。

扩散模型已经彻底改变了生成式AI,在生成逼真图像、3D模型、音频和视频方面取得了显著进展。然而,尽管这些模型取得了令人印象深刻的结果,但它们在采样时速度较慢。
我们正在分享一种新方法,称为sCM,它简化了连续时间一致性模型的理论公式,使我们能够稳定并扩展其训练以适应大规模数据集。这种方法在仅使用两个采样步骤的情况下实现了与领先扩散模型相当的样本质量。我们还将分享我们的研究论文,以支持该领域的进一步进展。

介绍
当前扩散模型的采样方法通常需要数十到数百个顺序步骤来生成单个样本,这限制了它们在实时应用中的效率和可扩展性。已经开发了各种蒸馏技术来加速采样,但它们通常伴随着限制,如高计算成本、复杂的训练和降低的样本质量。
在我们之前关于一致性模型的研究基础上,我们简化了公式并进一步稳定了连续时间一致性模型的训练过程。我们新的方法,称为sCM,使我们能够将连续时间一致性模型的训练扩展到前所未有的15亿参数,在ImageNet上以512×512分辨率进行训练。sCM可以在仅使用两个采样步骤的情况下生成与扩散模型相当的样本质量,从而实现约50倍的时钟速度提升。例如,我们最大的模型,拥有15亿参数,在单个A100 GPU上生成单个样本仅需0.11秒,无需任何推理优化。通过定制系统优化可以轻松实现额外加速,为图像、音频和视频等各个领域的实时生成开辟了可能性。
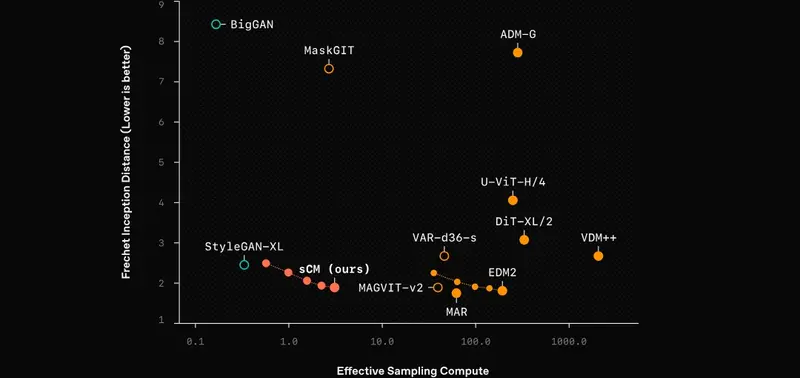
为了严格评估,我们通过比较样本质量和有效采样计算(估计生成每个样本的总计算成本),将sCM与其他最先进的生成模型进行了基准测试。如下图所示,我们的2步sCM生成的样本质量与之前最佳方法相当,而使用的有效采样计算不到10%,显著加速了采样过程。
工作原理
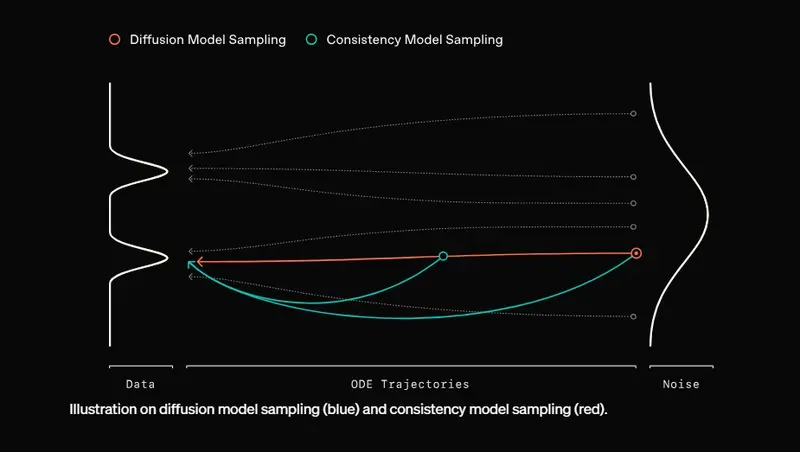
一致性模型为生成高质量样本提供了一种比传统扩散模型更快的替代方案。与通过大量去噪步骤逐步生成样本的扩散模型不同,一致性模型旨在通过单一步骤直接将噪声转换为无噪声样本。这种差异通过图中的路径可视化:蓝线表示扩散模型的逐步采样过程,而红线表示一致性模型的更直接、加速的采样。使用一致性训练或一致性蒸馏等技术,一致性模型可以训练为在显著更少的步骤中生成高质量样本,使其在需要快速生成的实际应用中具有吸引力。
我们在ImageNet 512x512上训练了一个拥有15亿参数的连续时间一致性模型,并提供了该模型的两步样本以展示其能力。

我们的sCM从预训练的扩散模型中提取知识。一个关键发现是,随着教师扩散模型和sCM的规模扩大,sCM的改进是成比例的。具体来说,样本质量的相对差异(由FID分数的比率衡量)在模型大小的几个数量级上保持一致,导致样本质量的绝对差异在规模上减小。此外,增加sCM的采样步骤进一步缩小了质量差距。值得注意的是,sCM的两步样本已经与教师扩散模型的样本相当(FID分数的相对差异小于10%),而教师扩散模型需要数百步才能生成样本。
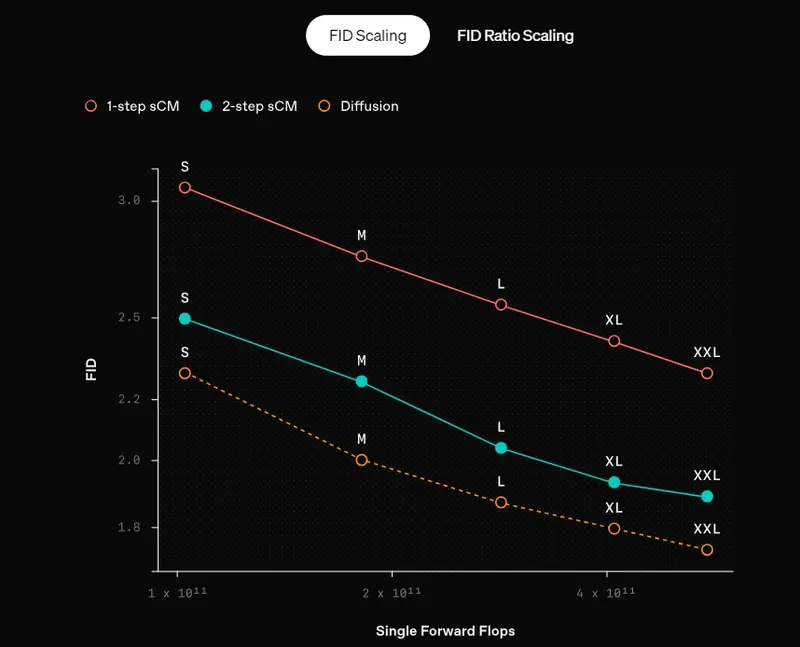
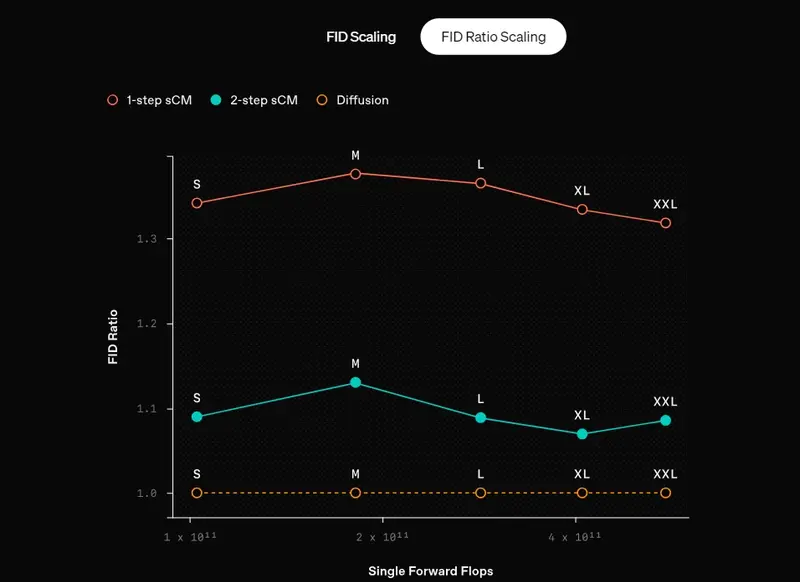
限制
最好的sCM仍然依赖于预训练的扩散模型进行初始化和蒸馏,导致与教师扩散模型相比,样本质量存在微小但一致的差距。此外,FID作为样本质量的指标有其自身的局限性;FID分数接近并不总是反映实际样本质量,反之亦然。因此,sCM的质量可能需要根据特定应用的要求以不同的方式进行评估。
下一步
我们将继续致力于开发具有改进推理速度和样本质量的更好的生成模型。我们相信这些进步将为各个领域的实时、高质量生成式AI开辟新的可能性。(来源)