俄勒冈州立大学和Adobe 研究中心的研究人员推出新型三维高斯重建模型Long-LRM,它能够快速从一系列输入图像中重建出一个大型场景的三维表示。例如,你是一位电影制作人,需要在一个复杂的城市环境中快速构建一个三维模型以用于特效制作。使用Long-LRM,你只需拍摄一系列该场景的照片,上传到计算机,模型就能迅速生成一个详细的三维城市环境,你可以从任何角度查看和修改这个环境,极大地提高了制作效率。
主要功能和特点:
- 快速重建:Long-LRM能够在短短1.3秒内处理32张960×540分辨率的源图像,并重建出整个场景。这对于需要即时三维场景重建的应用非常有帮助。
- 高效率:与需要长时间优化的传统方法相比,Long-LRM的重建效率高出两个数量级,这使得它在资源有限的环境中也非常有用。
- 高质量渲染:该模型能够生成高质量的新视角图像,与基于优化的方法相比,其渲染质量具有竞争力,甚至在某些情况下更优。
工作原理: Long-LRM的工作原理基于几个关键步骤:
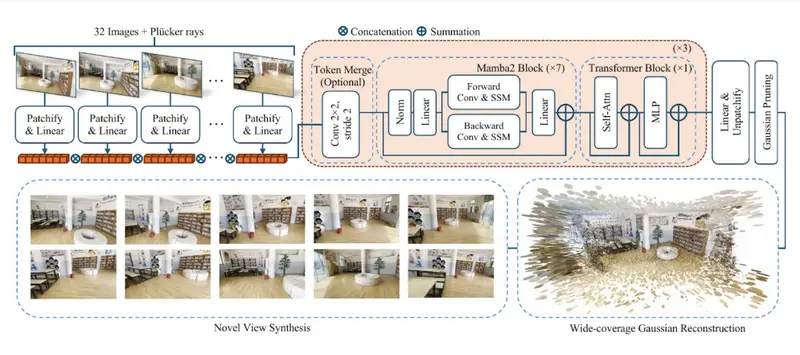
- 图像分块:首先,输入的多视角图像被分割成一系列的小块(patch tokens)。
- 序列处理:这些小块被线性变换并连接成 token 序列,然后通过一个混合了Mamba2块和传统transformer块的网络进行处理。Mamba2块有助于高效处理长序列数据,而transformer块则保留了全局上下文信息。
- 特征合并和高斯剪枝:在网络处理过程中,通过可选的token合并模块进一步减少token数量,并在渲染新视角之前对高斯参数进行剪枝,以提高效率。
- 新视角合成:处理后的token被解码成高斯参数,然后通过高斯剪枝生成最终的三维高斯表示,从而实现从新视角的高质量图像合成。
具体应用场景:
- 虚拟现实(VR)和增强现实(AR):在VR和AR应用中,Long-LRM可以快速为用户生成详细的三维环境模型,提升沉浸感。
- 三维内容创建:对于电影制作或游戏开发,Long-LRM可以加速三维场景的创建过程,减少手工建模的工作量。
- 自动驾驶和机器人:在这些领域,快速准确的三维场景理解对于导航和避障至关重要,Long-LRM可以提供实时的三维环境重建。