
基于大语言模型的评判者作为一种可扩展的人类评估替代方案已经出现,并且越来越多地用于评估、比较和改进模型。然而,基于大语言模型的评判者本身的可靠性很少受到审查。随着大语言模型变得更加先进,它们的响应变得更加复杂,需要更强的评判者来评估它们。现有的基准主要关注评判者与人类偏好的对齐,但往往未能考虑到更具挑战性的任务,在这些任务中,众包的人类偏好是事实和逻辑正确性的一个糟糕指标。
为了解决这个问题,加州大学伯克利分校和 圣路易斯华盛顿大学的研究人员推出评估框架JudgeBench,一个用于评估基于大语言模型的评判者在涵盖知识、推理、数学和编码的挑战性响应对上的基准。JudgeBench 利用了一种新颖的管道,将现有的困难数据集转换为具有反映客观正确性的偏好标签的挑战性响应对。
- GitHub:https://github.com/ScalerLab/JudgeBench
- 数据:https://huggingface.co/datasets/ScalerLab/JudgeBench
- 排行:https://huggingface.co/spaces/ScalerLab/JudgeBench
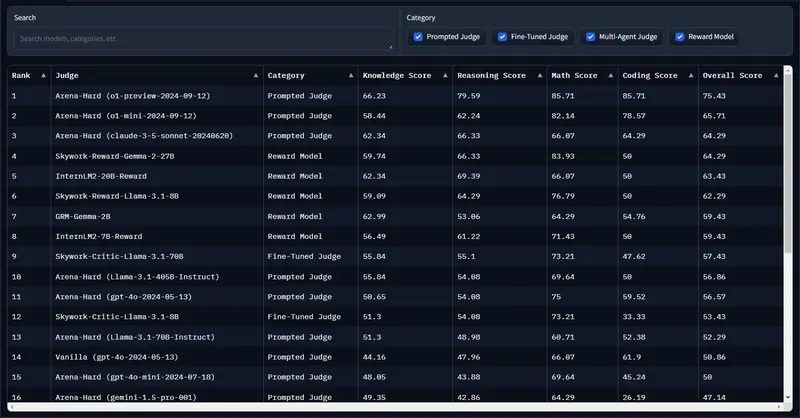
研究人员对一组提示评判者、微调评判者、多智能体评判者和奖励模型的全面评估显示,JudgeBench 比之前的基准提出了更大的挑战,许多强模型(例如 GPT-4o)的表现仅略好于随机猜测。总的来说,JudgeBench 为评估越来越先进的大语言模型评判者提供了一个可靠的平台。
例如,我们有两个AI模型,它们都试图回答一个复杂的数学问题。JudgeBench会生成两组回答,然后使用LLM裁判来评估哪个回答更好。如果裁判能够准确地识别出哪个回答是正确的,那么它就通过了测试。但如果裁判选择了错误的回应,那么它就需要进一步的训练和改进。通过这种方式,JudgeBench帮助我们确保AI裁判在评估其他AI模型时的可靠性和有效性。
主要功能和特点:
- 客观评估: JudgeBench通过一系列挑战性的任务来测试LLM裁判的客观性和准确性,这些任务包括知识问答、推理、数学和编程等。
- 多模态能力: 它评估的LLM裁判不仅能够处理文本数据,还能处理图像、视频和音频等多种类型的数据。
- 数据集转换: JudgeBench能够将现有的困难数据集转换成具有客观正确性标签的挑战性回应对,以便更好地测试LLM裁判的能力。
- 全面评估: 它不仅关注裁判与人类偏好的一致性,还考虑了在更复杂任务中裁判的逻辑和事实正确性。
工作原理:
JudgeBench的工作原理基于三个核心原则:首先,回应必须忠实地遵循人类的指令;其次,它应该提供事实和逻辑上正确的答案;最后,它的风格应该符合人类的偏好。基于这些原则,JudgeBench使用一系列复杂的数据集来测试LLM裁判,看它们是否能区分正确和错误的回应。
具体应用场景:
- AI模型开发: 在开发新的AI模型时,研究人员可以使用JudgeBench来评估和比较不同模型的性能。
- 教育和培训: 在教育领域,JudgeBench可以帮助评估教学AI模型,看它们是否能提供准确和逻辑一致的答案。
- 内容审核: 在内容审核领域,JudgeBench可以用于评估AI模型,以确保它们能够正确地识别和处理不当内容。