
文章目录[隐藏]
在构建开源和协作的人工智能(AI)过程中,我们面临着许多挑战。其中最显著的问题之一是AI模型开发的集中化,这种现象主要由拥有丰富资源的大型AI公司主导。这种权力的集中限制了更广泛社区参与AI开发的机会,使得高级AI技术难以普及。此外,训练大型AI模型所需的高昂成本和资源需求也阻碍了小型组织和个人为AI进步贡献力量。因此,提高AI开发的透明度和多样性显得尤为重要,以防止模型产生偏见并促进更多元化的视角。
INTELLECT-1 的发布
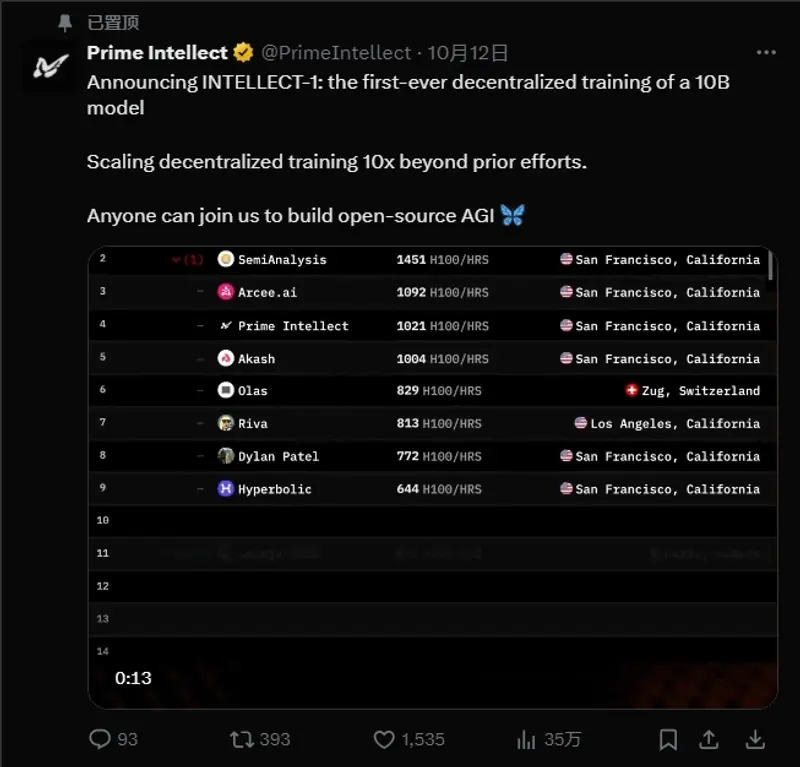
为了应对这些挑战,Prime Intellect AI 推出了 INTELLECT-1,这是首个100亿参数模型的去中心化训练运行。INTELLECT-1 邀请任何人贡献计算资源并参与其中,这一举措将去中心化AI训练的规模推向了前所未有的高度。通过将训练规模扩大10倍,Prime Intellect AI 致力于重新定义大规模AI模型的开发方式。
愿景:创建一个更具包容性的AI社区,让全球各地的参与者都能利用自己的计算能力为开源的通用人工智能(AGI)系统做出贡献。
参与方式:个人、小型组织和AI爱好者均可参与训练一个有望造福整个社会的模型,而不是局限于企业实验室的封闭环境。
INTELLECT-1 的技术细节与好处
从技术角度来看,INTELLECT-1 是一个100亿参数的模型训练,具备理解和生成类似人类对复杂查询的响应的能力,覆盖多种上下文。通过采用去中心化训练方法,Prime Intellect AI 利用了一个分布式计算资源网络,这些资源共同构成了进行大规模训练所需的力量。这种方法减少了对昂贵的集中式超级计算机的依赖,促进了从个人贡献者那里有效利用可用资源。
技术创新:
- 分布式计算:利用全球各地的计算资源,共同完成大规模训练任务。
- 高效工作负载分配:通过创新的协调技术,实现并行计算和缩短训练时间。
- 开放参与:参与者将获得前沿AI技术的经验,并贡献于一个真正开放的AI模型,该模型可供所有人使用,无需限制性许可协议。
INTELLECT-1 的重要性
INTELLECT-1 的发布具有多重重要意义:
- 挑战现状:打破了AI研究仅限于少数资金充足组织的局面,倡导开放协作作为技术进步的基础。
- 数据多样性:通过全球参与者的贡献,模型能够获取多样化的数据和观点,这是开发通用AI系统的关键要素。
- 社区驱动:强调开放性、透明度和集体所有权,有助于解决AI道德使用的问题,减少模型偏见。
- 社会里程碑:不仅是一个技术成就,更是创建一个服务于全体人类的AI系统的社会进步标志。
以下是官方介绍全文翻译:
INTELLECT-1是Prime Intellect启动的首个分布式训练的模型,参数10B,训练数据6T token,目前项目刚刚启动,邀请任何人贡献计算资源并参与。这使我们更接近开源AGI的目标。

最近的发展
最近,我们发布了OpenDiLoCo,这是DeepMind的分布式低通信(DiLoCo)方法的开源实现和扩展,使全球分布式AI模型训练成为可能。我们不仅复制并开源了这项工作,还成功将其扩展到10亿参数的规模。
现在,我们将其进一步扩展到100亿参数的模型规模,比原始研究高出约25倍。这使我们进入了我们的主计划的第三步:协作训练前沿开放基础模型:从语言、智能体到科学模型。
目标
我们的目标是逐步解决去中心化训练问题,以确保AGI将是开源、透明和可访问的,防止少数集中实体的控制并加速人类进步。
发布合作伙伴和贡献者
我们很高兴并感谢与Hugging Face、SemiAnalysis、Arcee、Hyperbolic、Olas、Akash、Schelling AI等领先的开放源AI参与者一起加入,为这次去中心化训练运行贡献计算资源。

如何贡献计算资源
任何人现在都可以通过我们的平台贡献资源来推进开源AI,稍后也可以更轻松地使用自己的硬件。
- 官网:https://www.primeintellect.ai
- 加入:https://primeintellect.ai/careers
- 训练进度查看:https://app.primeintellect.ai/intelligence
- GitHub:https://github.com/PrimeIntellect-ai/Prime
去中心化训练的范式转变
正如Anthropic的联合创始人Jack Clark所强调的,还没有任何模型能够在全球分布的工人中高效地训练到100亿参数的规模。我们的初始OpenDiLoCo运行突破了10亿参数的障碍,通过INTELLECT-1,我们达到了去中心化训练的新规模水平。
DiLoCo使AI模型能够在连接不良的设备群岛上进行训练。该方法允许在这些不同的群岛上进行数据并行训练,只需要每隔几百步同步伪梯度。它显著减少了通信频率(高达500倍),从而降低了分布式训练的带宽需求。
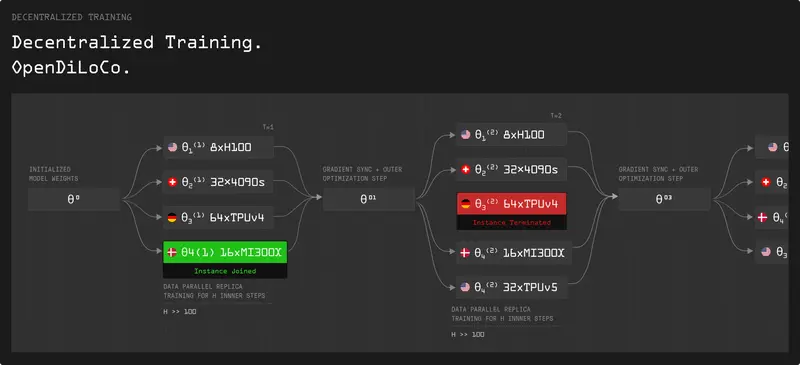
Prime:我们的去中心化训练框架
自我们最初的开放源代码发布以来,我们在两个关键维度上改进了我们的分布式训练框架:
1. 算法进展
我们基于OpenDiLoCo工作的许多消融实验显示了进一步减少通信需求的巨大潜力。特别是,我们对伪梯度的量化实验将带宽需求减少了高达2000倍,结合伪梯度的int8量化和每500步的外部优化器同步。这些结果在小规模上有效,我们很高兴将其扩展到更大的模型规模。
2. 可扩展的去中心化训练框架
分布式训练既是一个工程挑战,也是一个研究挑战。即使在最大的AI实验室中,实现跨分布式数据中心的容错训练也是他们今天努力解决的问题。
我们很高兴宣布发布一个新的去中心化训练框架Prime。Prime支持容错训练,支持计算资源的动态加入/退出,并优化了全球分布式GPU网络中的通信和路由。
该框架构成了我们开源技术栈的基础,旨在支持我们自己的和其他去中心化训练算法,超越OpenDiLoCo。通过构建在这个基础设施上,我们旨在推动全球分布式AI训练的可能性边界。
关键特性
- 弹性设备网格用于容错训练
- 异步分布式检查点
- 实时检查点恢复
- 自定义Int8 All-Reduce内核
- 最大化带宽利用率
PyTorch FSDP2 / DTensor ZeRO-3实现
为了在我们的给定内存资源内适应100亿模型训练,我们必须在节点内GPU之间分片模型权重、梯度和优化器状态。
我们通过使用PyTorch FSDP2的fully_shard API实现了这一点,该API将模型参数包装为DTensors,并在使用时为张量调度all-gather和reduce-scatter。FSDP2还通过将参数分组为FSDPParamGroups来优化集体,这使我们能够在大张量上执行集体,提高协议与有效载荷比率并改进流水线重叠。我们对伪梯度使用了相同的技巧,按层分组。
CPU卸载
我们的Diloco优化器不会增加任何GPU开销。Diloco优化器所需的所有张量都卸载到CPU内存中。
INTELLECT-1:首个去中心化训练的100亿参数模型
INTELLECT-1是一个基于Llama-3架构的100亿参数模型。
它将是第一个在这个规模上广泛训练于Hugging Face的Fineweb-Edu等最高质量开源数据集的模型。
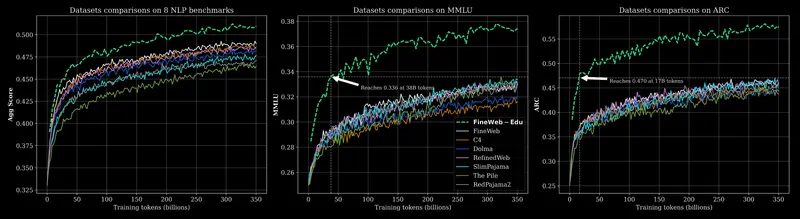
我们的精选数据混合包括以下内容:
- 55% Fineweb-edu
- 20% DLCM
- 20% Stack v2
- 5% OpenWebMath
我们使用WSD学习率调度器,在初始预热阶段后保持恒定的学习率。这种方法提供了根据计算贡献的数量灵活调整我们训练的Token数量的灵活性。在训练结束时,我们计划使用高质量数据集实施冷却阶段,以进一步提高性能,以及训练后的优化。
下一步:
INTELLECT-1只是第一步。我们将继续在我们的路线图上取得进展,将去中心化训练扩展到最大和最强大的开放前沿科学、推理和编码模型。
我们的路线图包括:
- 扩展到科学、推理和编码领域更大、更强大的开放前沿模型。
- 开发一个系统,允许任何人贡献自己的计算资源,使用证明机制确保对去中心化训练的安全和可验证贡献。
- 创建一个框架,使任何人都能发起去中心化训练运行,开放给他人贡献。